cudaDeviceSynchronize는 device에서 실행중인 모든 kernel이 종료될때까지 기다리는 함수이다.
덧셈연산
#include<cuda_runtime.h>__global__ voidvector_add(constfloat* A, constfloat* B, float* C, int N) {
int idx = threadIdx.x + blockIdx.x * blockDim.x;
int stride = blockDim.x * gridDim.x;
for(int i =idx;i<N;i+=stride) {
C[i] = A[i] + B[i];
}
}
voidsolve(constfloat* A, constfloat* B, float* C, int N) {
float*d_A, *d_B, *d_C;
// Allocate device memory
cudaMalloc(&d_A, N *sizeof(float));
cudaMalloc(&d_B, N *sizeof(float));
cudaMalloc(&d_C, N *sizeof(float));
// Copy input data from host to device
cudaMemcpy(d_A, A, N *sizeof(float), cudaMemcpyHostToDevice);
cudaMemcpy(d_B, B, N *sizeof(float), cudaMemcpyHostToDevice);
// Calculate grid and block dimensions
int threadsPerBlock =256;
int blocksPerGrid = (N + threadsPerBlock -1) / threadsPerBlock;
// Launch the kernel
vector_add<<<blocksPerGrid, threadsPerBlock>>>(d_A, d_B, d_C, N);
cudaDeviceSynchronize();
// Copy result back to host
cudaMemcpy(C, d_C, N *sizeof(float), cudaMemcpyDeviceToHost);
// Free device memory
cudaFree(d_A);
cudaFree(d_B);
cudaFree(d_C);
}
곱셈연산
#include<cuda_runtime.h>__global__ voidmatrix_multiplication_kernel(constfloat* A, constfloat* B, float* C, int M, int N, int K) {
int col = blockIdx.x * blockDim.x + threadIdx.x;
int row = blockIdx.y * blockDim.y + threadIdx.y;
if(row < M && col < K) {
float val =0.0;
for(int i =0;i<N;i++) {
val += A[(row*N) + i]*B[(K*i)+col];
}
C[(row*K)+col] = val;
}
}
// A, B, C are device pointers (i.e. pointers to memory on the GPU)
// A,B,C 가 device pointer이므로 cudaMalloc과 cudaMemcpy는 생략한다.
voidsolve(constfloat* A, constfloat* B, float* C, int M, int N, int K) {
dim3 threadsPerBlock(16, 16);
dim3 blocksPerGrid((K + threadsPerBlock.x -1) / threadsPerBlock.x,
(M + threadsPerBlock.y -1) / threadsPerBlock.y);
matrix_multiplication_kernel<<<blocksPerGrid, threadsPerBlock>>>(A, B, C, M, N, K);
cudaDeviceSynchronize();
}
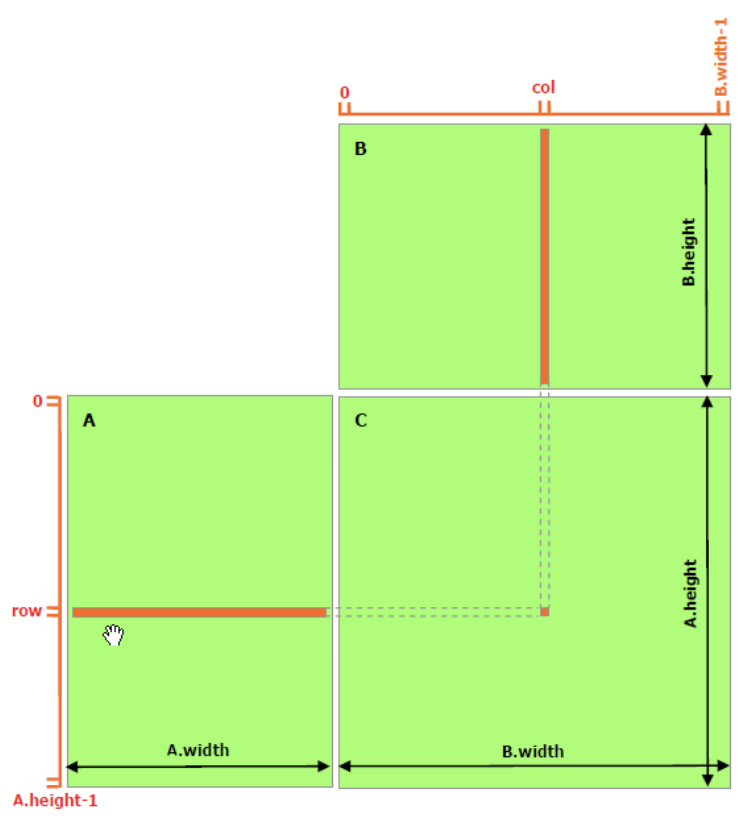
A matrix의 크기가 MxN이고 B matrix의 크기가 NxK일때, C matrix의 크기는 MxK인 곱셈을 수행한다.
이 구현은 꽤 Naive한 구현이다. 이 구현에서 CUDA Kernel은 DRAM을 사용하여 각 thread가 A와 B의 행렬을 곱하는 방식으로 동작한다. 조금더 개선된 속도를 위해
shared memory를 사용하여 A와 B의 행렬을 곱하는 방식이 있다. 구현은 다음과 같다.
#include<cuda_runtime.h>#define TILE_SIZE 16
__global__ voidmatrix_multiplication_kernel_with_shared_memory(constfloat* A, constfloat* B, float* C, int M, int N, int K) {
__shared__ float A_shared[TILE_SIZE][TILE_SIZE];
__shared__ float B_shared[TILE_SIZE][TILE_SIZE];
int col = blockIdx.x * TILE_SIZE + threadIdx.x;
int row = blockIdx.y * TILE_SIZE + threadIdx.y;
float val =0.0;
for(int i =0; i < (N + TILE_SIZE -1) / TILE_SIZE; i++) {
if(row < M && i * TILE_SIZE + threadIdx.x < N) {
A_shared[threadIdx.y][threadIdx.x] = A[row * N + i * TILE_SIZE + threadIdx.x];
} else {
A_shared[threadIdx.y][threadIdx.x] =0.0;
}
if(col < K && i * TILE_SIZE + threadIdx.y < N) {
B_shared[threadIdx.y][threadIdx.x] = B[(i * TILE_SIZE + threadIdx.y) * K + col];
} else {
B_shared[threadIdx.y][threadIdx.x] =0.0;
}
__syncthreads();
for(int j =0; j < TILE_SIZE; j++) {
val += A_shared[threadIdx.y][j] * B_shared[j][threadIdx.x];
}
__syncthreads();
}
if(row < M && col < K) {
C[row * K + col] = val;
}
}