FFT on GPU
Introduction
이 포스트에서 다룰것은 Fast fourier Transform이다. 이 알고리즘에대해서는 PS(Competitve programming) 하는 사람들은 익히 알것이다. 실제로 검색을해보면 알고리즘에 대해서는 상세히 알수가있다. 그렇기때문에 알고리즘을 톺아보기보다 GPU위에서 FFT를 구현하는것에대해 초점을 맞춰 글을 작성할 예정이다.
Background
Fourier Transform
Fourier Transform(푸리에 변환)은 신호를 주파수 성분으로 분해하는 수학적 기법이다. 이는 시간 도메인에서 표현된 신호를 주파수 도메인으로 변환하여, 신호의 주파수 특성을 분석하고 처리하는 데 사용된다. 푸리에 변환은 다양한 분야에서 활용되며, 특히 신호 처리, 이미지 처리, 음성 인식, 통신 시스템 등에서 중요한 역할을 한다. 정의는 이러한데 그렇다면 푸리에 변환은 이런 특정 도메인이 아니면 전혀 쓸모가 없는것일까? 익히 알려져있듯 이러한 도메인이아니라 일반적인 연산 영역에서도 푸리에 변환은 유용하게 사용될 수 있다. 이를 중점으로 살펴보자.
우선 푸리에 변환의 복잡한 수학적 정의는 생략하고 푸리에 변환이 주요 사용되는 지점들을 보면 신호와 같이 주기를 가지고 있는 데이터에서 유용하게 사용된다. 이런 주기성이 중요함을 인지하고 넘어가자.
Discrete Fourier Transform
실제 컴퓨터에서 다루는 데이터는 연속적인 신호가 아니라 이산적인 샘플로 표현된다. 따라서 푸리에 변환을 컴퓨터에서 구현하기 위해서는 이산 푸리에 변환(Discrete Fourier Transform, DFT)을 사용한다. DFT는 다음과 같이 정의된다: $$X_k = \sum_{n=0}^{N-1} x_n \cdot e^{-i \frac{2\pi}{N} kn}$$ 여기서:
- $X_k$: 주파수 도메인에서의 k번째 성분
- $x_n$: 시간 도메인에서의 n번째 샘플
- $N$: 샘플의 총 개수
- $e^{-i \frac{2\pi}{N} kn}$: 복소 지수 함수로, 주파수 변환을 수행하는 역할
이때 $e^{-i \frac{2\pi}{N} kn}$는 오일러 공식에 의해 다음과 같이 표현될 수 있다: $$e^{-i \frac{2\pi}{N} kn} = \cos\left(\frac{2\pi}{N} kn\right) - i \sin\left(\frac{2\pi}{N} kn\right)$$
이 수식에서 모든 $k$에 대해 모든 $n$을 순회하므로 DFT의 계산 복잡도는 $O(N^2)$이다. 샘플 수가 커질수록 계산 시간이 급격히 늘어나는데, 이를 줄이려면 수식 내부에 재활용 가능한 구조가 있어야 한다. $e^{-i\frac{2\pi}{N}kn}$ 항을 좀 더 자세히 들여다보자.
Primitive Root of Unity
복소 평면의 단위원($|z|=1$) 위에 $N$개의 점을 등간격으로 찍으면, 이 점들은 방정식 $z^N = 1$의 해가 된다. 이 해들 중 한 칸 회전에 해당하는 가장 기본적인 점을 primitive N-th root of unity라 하며 다음과 같이 정의한다: $$\omega_N = e^{-i \frac{2\pi}{N}}$$
나머지 점들은 $\omega_N$을 거듭제곱하면 전부 얻을수 있다: $\omega_N^0, \omega_N^1, \omega_N^2, \ldots, \omega_N^{N-1}$. 이 표기를 사용하면 DFT는 다음과 같이 간결하게 다시 쓸수 있다: $$X_k = \sum_{n=0}^{N-1} x_n \cdot \omega_N^{kn}$$
이게 단순히 표기를 줄인것에 불과하다면 굳이 도입할 이유가 없다. 핵심은 $\omega_N$이 가지는 대수적 성질에 있다. FFT를 가능하게 하는 세 가지 성질을 살펴보자:
- 주기성: $\omega_N^N = 1$ — 지수가 $N$을 넘으면 다시 처음으로 돌아온다.
- 대칭성: $\omega_N^{N/2} = -1$ — 단위원에서 정반대 점이므로 부호가 뒤집힌다. 따라서 $\omega_N^{k+N/2} = -\omega_N^k$이다.
- 축소(Halving): $\omega_N^{2k} = \omega_{N/2}^k$ — 제곱하면 $N$-th root가 $N/2$-th root로 바뀌어 문제 크기가 절반이 된다.
이 세 성질이 왜 중요한지는 FFT의 유도 과정에서 바로 드러난다.
Fast Fourier Transform
FFT는 위 성질들을 활용하여 DFT의 $O(N^2)$를 $O(N \log N)$으로 줄이는 알고리즘이다. 가장 널리 알려진 Cooley-Tukey 알고리즘을 따라가며 유도해보자.
DFT 수식에서 인덱스 $n$을 짝수($2m$)와 홀수($2m+1$)로 나누면: $$X_k = \sum_{m=0}^{N/2-1} x_{2m} \cdot \omega_N^{2mk} + \sum_{m=0}^{N/2-1} x_{2m+1} \cdot \omega_N^{(2m+1)k}$$
두 번째 항에서 $\omega_N^k$를 밖으로 빼면: $$X_k = \sum_{m=0}^{N/2-1} x_{2m} \cdot \omega_N^{2mk} + \omega_N^k \sum_{m=0}^{N/2-1} x_{2m+1} \cdot \omega_N^{2mk}$$
여기서 축소 성질 $\omega_N^{2mk} = \omega_{N/2}^{mk}$를 적용하면: $$X_k = \underbrace{\sum_{m=0}^{N/2-1} x_{2m} \cdot \omega_{N/2}^{mk}}_{E_k} + \omega_N^k \underbrace{\sum_{m=0}^{N/2-1} x_{2m+1} \cdot \omega_{N/2}^{mk}}_{O_k}$$
$E_k$와 $O_k$는 각각 크기 $N/2$인 DFT이다. 그리고 대칭성 $\omega_N^{k+N/2} = -\omega_N^k$에 의해: $$X_{k+N/2} = E_k - \omega_N^k \cdot O_k$$
즉 $E_k$와 $O_k$를 한 번 구하면 $X_k$와 $X_{k+N/2}$를 동시에 얻을수 있다. 이것이 butterfly 연산이다. 크기 $N$ 문제가 크기 $N/2$ 문제 2개 + $O(N)$ 결합으로 분할되므로: $$T(N) = 2T(N/2) + O(N) = O(N \log N)$$
$\omega_N$의 성질 세 가지가 없었다면 이 분할은 불가능했을 것이다. 이제 이 알고리즘을 다항식 곱셈에 적용해보자.
다항식 곱셈과 FFT
다항식의 두 가지 표현
다항식을 표현하는 방법에는 두 가지가 있다.
계수 표현: 우리가 일반적으로 사용하는 형태이다. $$A(x) = a_0 + a_1 x + a_2 x^2 + \cdots + a_{n-1} x^{n-1}$$
점값 표현: 서로 다른 $N$개의 점에서의 함수값으로 다항식을 나타내는 방법이다. $${(x_0, A(x_0)),\ (x_1, A(x_1)),\ \ldots,\ (x_{N-1}, A(x_{N-1}))}$$
$n-1$차 다항식은 $n$개의 서로 다른 점에서의 값으로 유일하게 결정되므로 두 표현은 동치이다.
점값 표현이 강력한 이유는 곱셈에 있다. 두 다항식 $A(x)$, $B(x)$의 곱 $C(x) = A(x) \cdot B(x)$를 점값 표현에서 구하면, 같은 점에서의 값을 그냥 곱하기만 하면 된다: $$C(x_k) = A(x_k) \cdot B(x_k)$$
이것은 $O(N)$이다. 반면 계수 표현에서의 직접 곱셈은: $$c_k = \sum_{i=0}^{k} a_i \cdot b_{k-i}$$
이 convolution 연산은 $O(n^2)$이다. 그렇다면 전략은 명확하다.
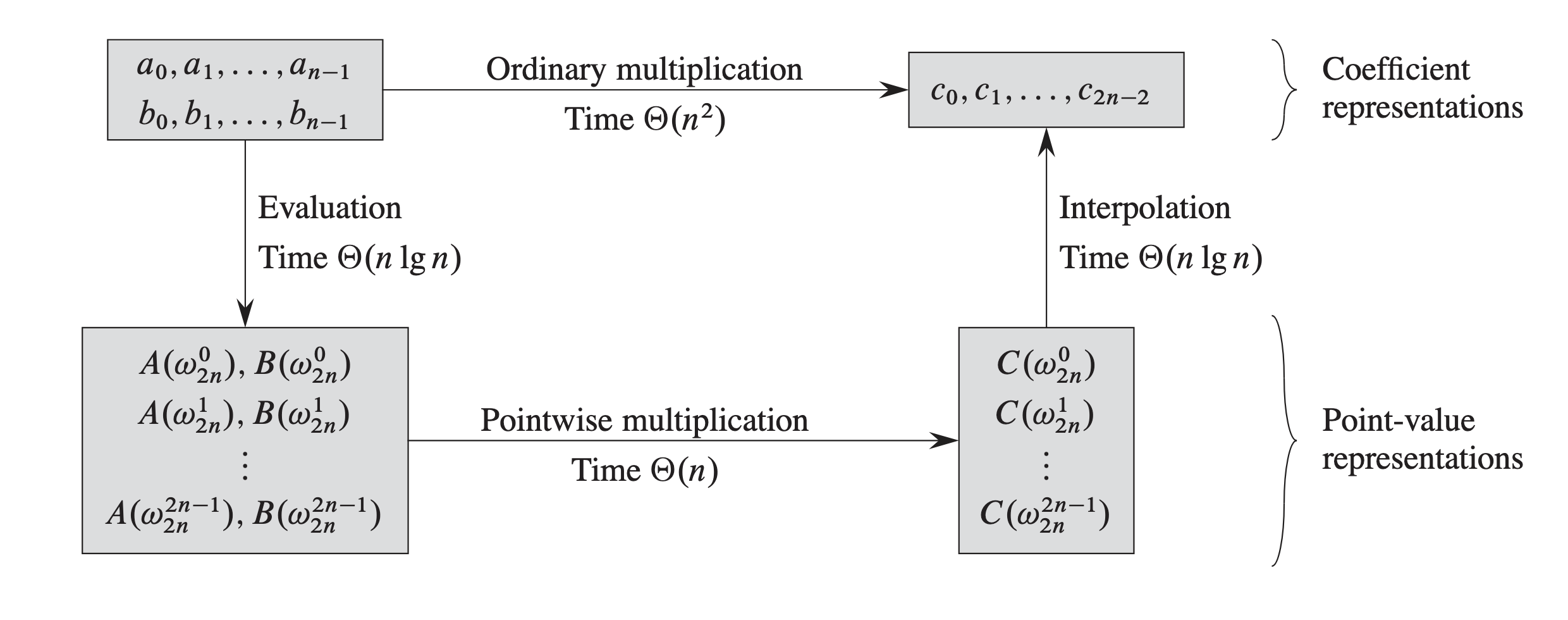
계수 표현 → 점값 표현 (변환) → 점별 곱셈 $O(N)$ → 점값 표현 → 계수 표현 (역변환)
이 전략이 의미를 가지려면 변환과 역변환이 $O(n^2)$보다 빨라야 한다.
왜 Root of Unity를 대입점으로 고르는가
임의의 $N$개 점에 다항식을 대입하면 각 점마다 $O(N)$, 점이 $N$개이므로 총 $O(N^2)$이다. 아무 점이나 골라서는 나아질게 없다.
여기서 핵심적인 관찰이 등장한다. 다항식 $A(x)$에 $\omega_N^k$를 대입하면: $$A(\omega_N^k) = \sum_{j=0}^{n-1} a_j \cdot \omega_N^{jk}$$
이것은 계수 $a_j$에 대한 DFT와 정확히 같은 형태이다. 다시 말해 다항식을 roots of unity에서 평가하는 것이 곧 DFT이다. 다항식 자체에 주기성이 있어서가 아니다. 주기적 구조를 가진 점들을 대입점으로 선택한 것이고, 그 점들이 가진 대칭성과 축소 성질 덕분에 앞서 유도한 FFT를 그대로 적용하여 $O(N \log N)$에 평가할수 있는것이다.
역변환(점값 → 계수) 역시 깔끔하다: $$a_j = \frac{1}{N} \sum_{k=0}^{N-1} A(\omega_N^k) \cdot \omega_N^{-jk}$$
$\omega_N$을 $\omega_N^{-1}$로 바꾸고 $\frac{1}{N}$을 곱한것 뿐이므로, 역변환도 FFT와 같은 구조로 $O(N \log N)$에 수행할수 있다. 만약 임의의 점을 골랐다면 역변환은 Vandermonde 행렬의 역행렬을 구해야 하므로 이렇게 깔끔하게 떨어지지 않는다.
전체 과정
정리하면 두 다항식 $A(x)$, $B(x)$의 곱셈은 다음과 같이 수행된다:
- $A(x)$와 $B(x)$의 계수 벡터에 FFT를 적용하여 점값 표현으로 변환 — $O(N \log N)$
- 변환된 점값을 요소별로 곱셈 — $O(N)$
- 결과에 역 FFT(IFFT)를 적용하여 계수 표현으로 복원 — $O(N \log N)$
결국 두 다항식의 곱셈을 $O(N \log N)$에 수행할수 있게 된다. 전체적인 흐름을 다이어그램으로 보면 다음과 같다.
FFT on GPU
우선 naive한 CUDA 구현체는 다음과 같다
#include <cuda_runtime.h>
#include <cmath>
#include <iostream>
__global__ void copykernel(const float* input, float* output, int n) {
int idx = blockDim.x * blockIdx.x + threadIdx.x;
if(idx < 2*n) {
output[idx] = input[idx];
}
}
__global__ void bitReverseKernel(float *input,int n, int lgn) {
int idx = blockDim.x*blockIdx.x + threadIdx.x;
if(idx < n) {
int rev = 0;
int tmp = idx;
for(int i =0;i<lgn;i++) {
rev = (rev<< 1) | (tmp & 1);
tmp >>=1;
}
if(idx<rev){
float a0 = input[2*idx];
float a1 = input[2*idx+1];
float b0 = input[2*rev];
float b1 = input[2*rev+1];
input[2*idx] = b0;
input[2*idx+1] = b1;
input[2*rev] = a0;
input[2*rev+1] = a1;
}
}
}
__global__ void fft_kernel(float* input,int n,int depth) {
int half = 1 << depth;
int stride = half << 1;
int idx= blockDim.x * blockIdx.x + threadIdx.x;
if (idx < n) {
int pos = idx%stride;
if (pos < half) {
int i = idx;
int j = half + i;
float xr = input[2*i];
float xi = input[2*i+1];
float yr = input[2*j];
float yi = input[2*j+1];
float angle = M_PI * pos / half;
float wr = cosf(angle);
float wi = -sinf(angle);
float tr = wr * yr - wi * yi;
float ti = wi * yr + wr * yi;
input[2*i] = xr + tr;
input[2*i+1] = xi + ti;
input[2*j] = xr - tr;
input[2*j+1] = xi - ti;
}
}
}
__global__ void dft(const float* input, float* output ,int n) {
int k = blockDim.x * blockIdx.x + threadIdx.x;
if (k < n) {
float sumRe = 0.0f;
float sumIm = 0.0f;
for (int t = 0; t < n; t++) {
float angle = -2.0f * M_PI * k * t / n;
float wr = cosf(angle);
float wi = sinf(angle);
float xr = input[2*t];
float xi = input[2*t + 1];
sumRe += xr * wr - xi * wi;
sumIm += xr * wi + xi * wr;
}
output[2*k] = sumRe;
output[2*k + 1] = sumIm;
}
}
extern "C" void solve(const float* signal, float* spectrum, int N) {
int lgn = 0;
int tempN = N;
while (tempN >>= 1) ++lgn;
if((N & (N - 1)) != 0) {
int threadsPerBlock = 256;
int blocksPerGrid = (N + threadsPerBlock - 1) / threadsPerBlock;
dft<<<blocksPerGrid, threadsPerBlock>>>(signal,spectrum, N);
cudaDeviceSynchronize();
return;
}
else {
int threadsPerBlock = 256;
int blocksPerGrid = (2*N + threadsPerBlock - 1) / threadsPerBlock;
copykernel<<<blocksPerGrid, threadsPerBlock>>>(signal, spectrum, N);
cudaDeviceSynchronize();
blocksPerGrid = (N + threadsPerBlock - 1) / threadsPerBlock;
bitReverseKernel<<<blocksPerGrid, threadsPerBlock>>>(spectrum, N, lgn);
cudaDeviceSynchronize();
for(int s = 0; s < lgn; s++) {
fft_kernel<<<blocksPerGrid, threadsPerBlock>>>(spectrum, N, s);
cudaDeviceSynchronize();
}
}
}
fft_kernel 의 경우 각 스레드가 하나의 butterfly 연산을 수행한다. bitReverseKernel은 입력 데이터를 비트 반전 순서로 재배열한다. solve 함수는 입력 신호가 2의 거듭제곱 크기가 아닌 경우 DFT를 사용하고, 그렇지 않은 경우 FFT를 수행한다.
reverse bit order
비트반전은 cooley-tukey 알고리즘 구현에서 성능면에서 중요한 역할을 한다. divide - conquer 과정을 생각해보자.
[x0, x1, x2, x3, x4, x5, x6, x7] 이라는 입력이 있다고하자. 이 입력을 짝수와 홀수로 나누면
- 짝수:
[x0, x2, x4, x6] - 홀수:
[x1, x3, x5, x7]이 된다. 한번더 재귀적으로 반복하면 - 짝수의 짝수:
[x0, x4] - 짝수의 홀수:
[x2, x6] - 홀수의 짝수:
[x1, x5] - 홀수의 홀수:
[x3, x7]이 된다. 이를 다시 합치면[x0, x4, x2, x6, x1, x5, x3, x7]이 순서가 바로 비트 반전 순서이다. 인덱스를 3비트 이진수로 표현하면 다음과 같다[000, 100, 010, 110, 001, 101, 011, 111]이고 이를 뒤집으면[000, 001, 010, 011, 100, 101, 110, 111]이 된다. 즉 비트 반전 순서로 데이터를 재배열하면 divide - conquer 과정에서의 메모리 접근 패턴이 개선되어 캐시 효율성이 높아지고, 병렬 처리 시 스레드 간의 동기화가 용이해진다.
Imporvements
shared memory 사용
Algorithm per signal Length
지금까지 살펴본 FFT 알고리즘은 입력 신호의 길이가 2의 거듭제곱일 때 가장 효율적이다. 그러나 실제 신호는 항상 그런것이 아니다. 이럴때는 여러 전략을 필요로 한다.
-
Zero Padding: 입력 신호의 길이를 가장 가까운 2의 거듭제곱으로 늘리기 위해 0으로 채우는 방법이다. 이 방법은 구현이 간단하고 FFT 알고리즘을 그대로 사용할 수 있지만, 추가된 0이 결과에 영향을 미칠 수 있다.
-
Mixed-Radix FFT: 입력 신호의 길이가 2의 거듭제곱이 아닐 때도 효율적으로 처리할 수 있는 알고리즘이다. 예를 들어, 길이가 12인 신호는 3과 4의 곱이므로, 3-점과 4-점 FFT를 결합하여 처리할 수 있다. 이 방법은 다양한 길이의 신호에 대해 유연하게 대응할 수 있다.
-
Bluestein’s Algorithm: 임의의 길이의 신호에 대해 FFT를 수행할 수 있는 알고리즘이다. 이 방법은 입력 신호를 특정한 방식으로 변환하여, 길이가 2의 거듭제곱인 신호로 바꾸고, 그 후에 FFT를 적용한다. 이 방법은 모든 길이의 신호에 대해 적용 가능하지만, 구현이 복잡하다.
-
Rader’s Algorithm: 소수 길이의 신호에 대해 FFT를 수행할 수 있는 알고리즘이다. 이 방법은 입력 신호를 순환 컨볼루션으로 변환하여, 길이가 2의 거듭제곱인 신호로 바꾸고, 그 후에 FFT를 적용한다. 이 방법 역시 구현이 복잡하다.