..
Gpu_architec
Introduction
gpu programming을 하기위해서는 gpu architecture에 대한 이해가 필요하다. gpu가 무엇인지는 현재에와서는 모르는 사람이 없을것이다. 때문에 gpu에 대한 소개는 생략하고 gpu architecture를 곧바로 살펴보자
GPU Hardware Architecture
gpu architecture는 크게 다음과 같은 요소로 구성된다.
- Streaming Multiprocessors (SMs): GPU의 핵심 컴퓨팅 유닛으로, 병렬 처리를 수행한다. 각 SM은 여러 개의 CUDA 코어를 포함하고 있으며, 동시에 여러 스레드를 실행할 수 있다.
- HBM (High Bandwidth Memory): GPU의 글로벌 메모리로, 데이터 전송 속도가 매우 빠르다. HBM은 GPU와 CPU 간의 데이터 전송을 최적화하여 높은 성능을 제공한다. DRAM을 적층해 만든 구조로 CPU에서 DRAM의 역할과 유사하다.
- L2 Cache: GPU의 L2 캐시는 데이터 접근 속도를 높이기 위해 사용된다. L2 캐시는 GPU와 HBM 사이의 중간 캐시 역할을 하며, 자주 사용되는 데이터를 저장하여 빠른 접근을 가능하게 한다.
- NVLink: 다른 GPU와의 연결을 위한 인터페이스로 , 다중 GPU 시스템에서 높은 대역폭을 제공한다. NVLink는 GPU 간의 데이터 전송 속도를 향상시켜, 병렬 처리 성능을 극대화한다.
Streaming Multiprocessors (SMs)
SMs는 GPU의 핵심 컴퓨팅 유닛으로, 병렬 처리를 수행한다. 각 SM은 다음과 같은 구성 요소로 이루어져 있다:
- CUDA Cores: SM 내에서 실제 연산을 수행하는 유닛이다. 하나의 코어는 단일 스레드의 연산을 처리한다.
- Tensor Cores: 딥러닝 연산을 가속화하기 위해 설계된 유닛으로, 행렬 연산을 효율적으로 처리한다. Tensor Cores는 FP16 및 INT8 데이터 타입을 지원하여 높은 성능을 제공한다.
- Warp: SM 내에서 실행되는 스레드 그룹으로, 32개의 스레드로 구성된다. 각 워프는 동시에 실행되며, GPU의 병렬 처리 능력을 극대화한다. 워프는 스케줄러에 의해 관리되며, 스레드 간의 동기화를 지원한다.
- Warp Scheduler: SM 내에서 실행될 스레드를 관리하는 유닛이다. 각 SM은 여러 개의 워프(32개의 스레드로 구성)를 동시에 실행할 수 있다.
- Registers: 각 CUDA 코어가 사용하는 로컬 메모리로, 빠른 데이터 접근을 가능하게 한다. 각 스레드는 자신의 레지스터를 사용하여 데이터를 저장하고 처리한다.
- L1 Cache: 각 SM 내에서 사용되는 캐시로, 데이터 접근 속도를 높이기 위해 사용된다. L1 캐시는 Shared Memory와 Registers의 역할을 하며, 자주 사용되는 데이터를 저장하여 빠른 접근을 가능하게 한다.
- Instruction Cache: SM 내에서 실행되는 명령어를 캐싱하여, 명령어 접근 속도를 높인다. 이 캐시는 자주 사용되는 명령어를 저장하여, 반복적인 연산의 성능을 향상시킨다.
- Texture Units: GPU에서 텍스처 데이터를 처리하는 유닛으로, 이미지 및 비디오 처리에 사용된다. 텍스처 유닛은 고속의 텍스처 캐시를 사용하여, 이미지 데이터를 효율적으로 처리한다.
이 외에도 다른 구성 요소가 있지만, 위의 요소들이 GPU의 핵심적인 역할을 한다. 자세한 사항은 아래 그림을 참고하자.
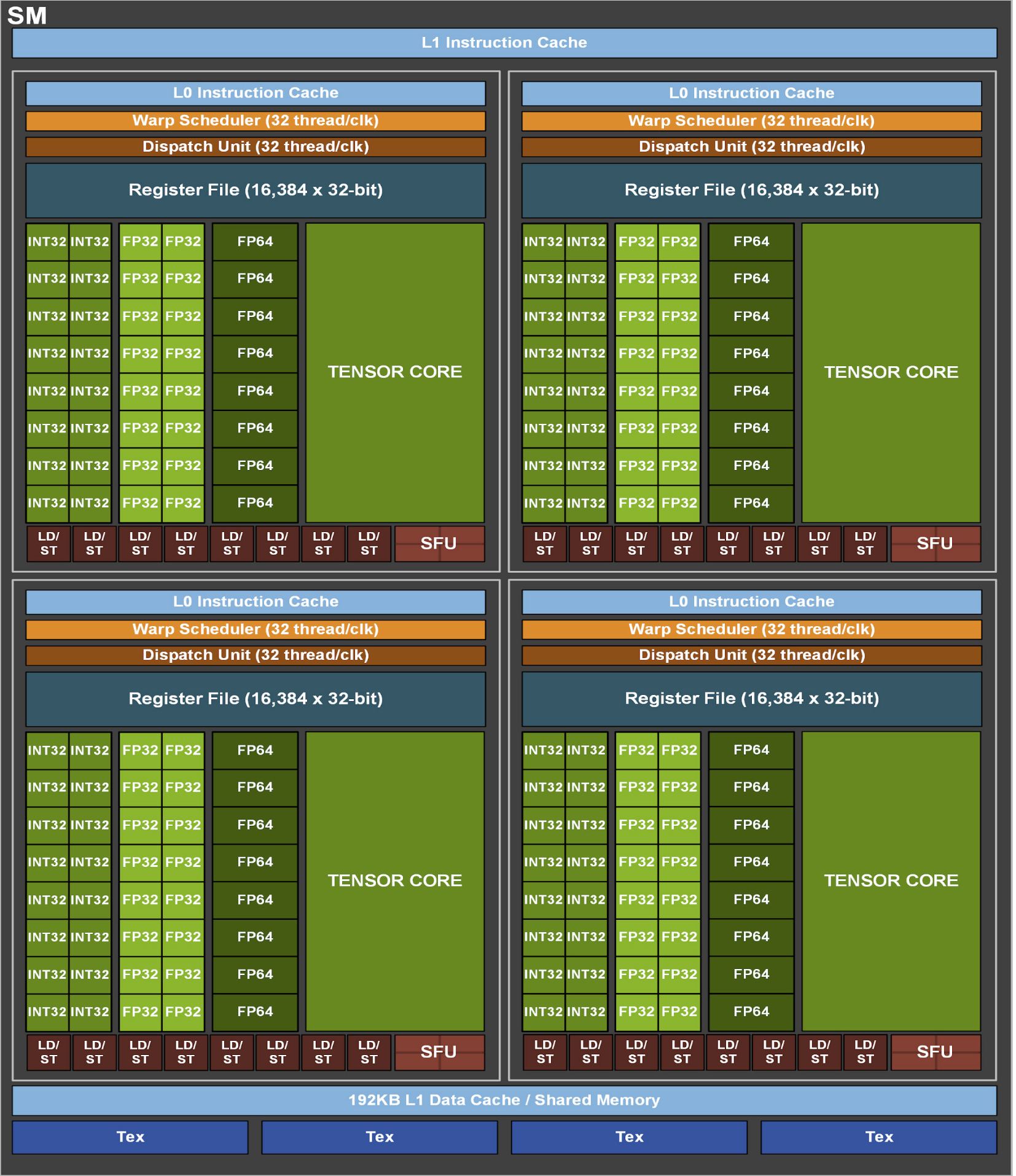
위 그림은 A100의 SM구조로 각 SM은 108개의 CUDA 코어, 4개의 Tensor Cores, 64KB의 L1 캐시 및 96KB의 Shared Memory를 갖추고 있다.
GPU의 논리적 구조
GPU의 하드웨어 구조를 살펴보았으니 GPU는 논리적으로 다음과 같은 구조를 살펴보자
- Global Memory: GPU의 메인 메모리로, 모든 SM이 접근할 수 있는 데이터 저장 공간이다. Global Memory는 대용량 데이터를 저장할 수 있지만, 접근 속도가 상대적으로 느리다. GPU의 Global Memory는 CPU의 DRAM과 유사하다.
- Grid: GPU에서 실행되는 커널(함수) 실행의 논리적 단위로, 여러 개의 블록으로 구성된다.
- Block: 각 블록은 여러 개의 스레드로 구성되며, 동일한 Shared Memory를 공유한다. 블록은 GPU의 SM에 할당되어 병렬로 실행된다.
- Thread: 블록 내에서 실행되는 개별 스레드로, 각 스레드는 자신의 레지스터와 Shared Memory를 사용하여 연산을 수행한다. 각 스레드는 독립적으로 실행되며, 다른 스레드와 동기화가 필요하다. CUDA core 혹은 Tensor core 1개가 하나의 스레드를 처리한다.
- Shared Memory: 각 블록 내에서 사용되는 빠른 메모리로, 블록 내의 모든 스레드가 공유할 수 있다. Shared Memory는 Global Memory보다 빠른 접근 속도를 제공하며, 블록 내의 스레드 간 데이터 공유를 가능하게 한다. SM내에 L1 캐시와 함께 존재하며, 메모리의 크기는 GPU의 Compute Capability에 따라 다르다. 예를 들어, Compute Capability 7.0인 A100 GPU는 각 SM당 192KB의 shared meomory/ L1 캐시를 갖는다. A100의 경우 Shared memory에 0 KB에서 164KB까지 할당할 수 있다.[^3]
- Register: 각 스레드가 사용하는 로컬 메모리로, 가장 빠른 데이터 접근 속도를 제공한다. 레지스터는 각 스레드의 상태를 저장하며, 연산에 필요한 데이터를 임시로 저장한다.
- Local Memory: 각 스레드가 사용하는 메모리로, 레지스터에 저장할 수 없는 큰 데이터나 배열을 저장하는 데 사용된다. Local Memory는 Global Memory보다 느리지만, Shared Memory보다 빠르다. Compute capability 2.0 이상인 GPU의 경우, local memory 데이터는 SM의 L1 캐시와 device L2 캐시에 저장된다.
나중에 살펴볼 자료
H100 이후에 생긴 GPU 아키텍쳐의 특징이있다. 다음에 살펴보자
- Distributed Shared Memory: H100 GPU는 Distributed Shared Memory를 도입하여, 여러 GPU 간의 메모리 공유를 가능하게 한다. 이를 통해 다중 GPU 시스템에서 데이터 전송 속도를 향상시킨다.
- Thread Block Clustering: 여러 SM에서 실행되는 스레드 블록을 클러스터링하여 제어할수 있게해준다.
GPU 데이터 흐름
GPU의 데이터 흐름은 다음 그림과 같다.
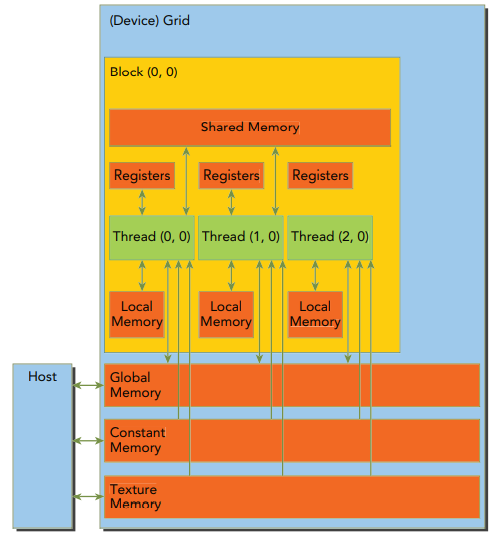
Host, 즉 CPU로 부터 할당받은 데이터를 GPU의 Global Memory, Texture memory, Constant memory에 올린다. 이 메모리의 데이터는 Block내의 Thread가 접근할 수 있다. 각 Block은 SM에 할당되어 병렬로 실행되며, 각 Block 내의 Thread는 Shared Memory를 통해 데이터를 공유한다. 각 Thread는 자신의 레지스터를 사용하여 연산을 수행한다.