Matryoshka Representation Learning Review
blog도 개설한겸 논문한편을 리뷰해보고자 한다. 정말 오랜만에 작성하는 리뷰이다. 이 논문의 제목은 Matryoshka Representation Learning 으로 Neurips'22 에 accept된 논문이다.
학습된 representation (예를 들어 encoder로 embedding된 sentence 등)은 다양한 다운스트림 task에 활용된다. Bert 계열의 encoder의 embedding출력값이 768차원으로 고정되듯 각 다운스트림 task에서 고정된 표현은 부족하거나 과할 수 있다. 이 때 적절한 차원으로의 축소 역시 그 크기를 정하는데 많은 리소스를 사용해야만 한다. 이 논문은 마트료시카 표현 학습 방법(MRL)을 제시함으로써 인코더가 다양한 정보로 표현을 임베딩해 다운스트림 task에 적응하는 방법을 제시한다. MRL을 통해 학습된 표현은 단일모델로 학습된 동일한 차원의 표현만큼 잘 학습한다.
방법은 간단하다. 그림과 같이 임베딩된 $z$에대해 $O(log(d))$개의 임베딩을 생성한다. 이때 단순히 원본임베딩을 자르기만한다. $z_{1:2},z_{1:4},z_{1:8} … z_{1:d}$ 의 임베딩들에 대해서 각각 linear classifier를 태우고 독립적으로 학습시킨다. multi-class softmax cross entropy loss func를 이용해 loss를 구하고 모든 loss를 합쳐 모델을 동시에 학습시킨다. 이게 전부이다. MRL-E (Efficient - MRL) 은 linear classifier를 하나로 합친다. 이때 $W \in \mathbb{R}^{L \times d}$ 는 $z$의 크기에 맞춰지고 $W_m = W_{1:m}$ 으로 볼 수 있다. (이 방법이 정말 마트료시카랑 비슷한듯). 추가로 adpative classification, retrieval 같은 방법을 사용해 동적으로 표현 크기를 조절 가능하다고 한다.
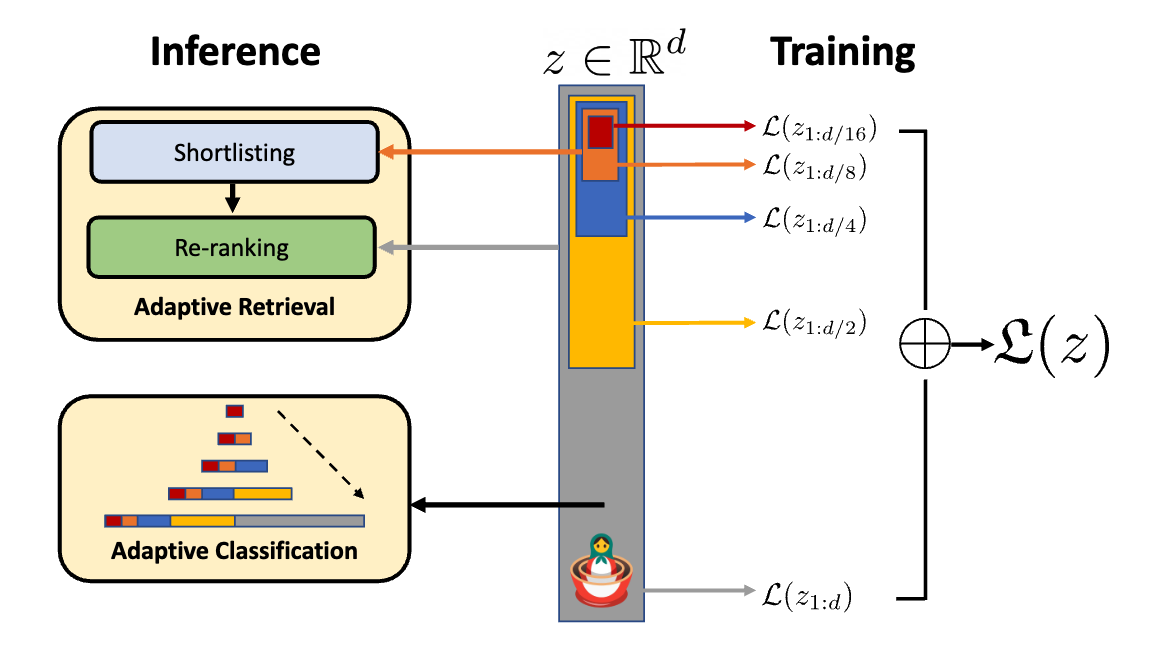 *Figure 1 *
*Figure 1 *
논문은 주로 비젼 task에대해서 실험했음으로 생략하고 이를 NLP 에 활용한 후속 논문인 2D Matryoshka Sentence Embedding 논문을 대충 살펴본다.
이 논문은 특히 transformer의 모든 layer에 대해 MRL을 적용한다. 학습시에 MRL과 동일하게 마지막 임베딩을 학습하고, 추가로 무작위로 중간 레이어를 선택해 MRL을 적용한다. 또 두 임베딩 loss사이의 KL divergence를 적용해 align 을한다(분포차이를 작게함). 이렇게 전체 loss를 더해 총 loss로 모델을 학습하게된다. 논문에서는 MRL처럼 모든 trunc size를 학습하는게아니라 선택된 크기로 잘라서 그 차원의 임베딩만 학습한다. 또한 여기서 필요에 따라 얕은 레이어의 임베딩만 사용함으로써 inference 속도를 빠르게 할 수 있다.
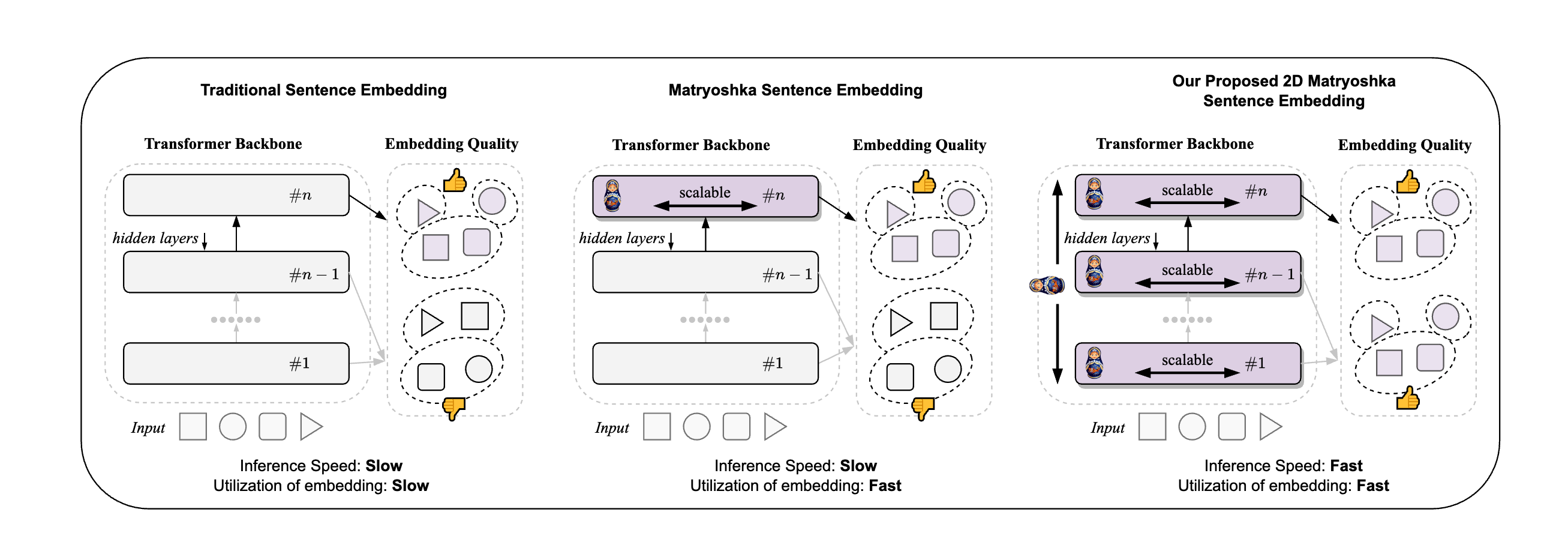 Figure 2
Figure 2
Sentence Transformer 사용법
sentence library에 구현이 되어있다. 사용법을 document에서 가져와봤다. 학습의 경우 간단히 loss를 설정해주면된다.
from sentence_transformers import SentenceTransformer
from sentence_transformers.losses import CoSENTLoss, MatryoshkaLoss
model = SentenceTransformer("microsoft/mpnet-base")
base_loss = CoSENTLoss(model=model)
loss = MatryoshkaLoss(model=model, loss=base_loss,
matryoshka_dims=[768, 512, 256, 128, 64])
loss = Matryoshka2dLoss(model=model, loss=base_loss,
matryoshka_dims=[768, 512, 256, 128, 64])
inference는 다음과 같다.
from sentence_transformers import SentenceTransformer
import torch.nn.functional as F
matryoshka_dim = 64
model = SentenceTransformer(
"nomic-ai/nomic-embed-text-v1.5",
trust_remote_code=True,
truncate_dim=matryoshka_dim,
)
embeddings = model.encode(
[
"search_query: What is TSNE?",
"search_document: t-distributed stochastic neighbor embedding (t-SNE) is a statistical method for visualizing high-dimensional data by giving each datapoint a location in a two or three-dimensional map.",
"search_document: Amelia Mary Earhart was an American aviation pioneer and writer.",
]
)
assert embeddings.shape[-1] == matryoshka_dim
similarities = model.similarity(embeddings[0], embeddings[1:])
# => tensor([[0.7839, 0.4933]])
작은 사이즈의 임베딩 크기를 설정하여도 search_query 에대해서 무관한 문서보다 유관한 문서의 유사성이 높게 나타났다.
GPT-4 turobo에도 embedding 방법을 활용하는듯 하다.^
Reference
- Kusupati, Aditya, et al. “Matryoshka representation learning.” Advances in Neural Information Processing Systems 35 (2022): 30233-30249. https://arxiv.org/pdf/2205.13147v4
- https://github.com/RAIVNLab/MRL
- https://huggingface.co/blog/matryoshka
- Li, Xianming, et al. “2d matryoshka sentence embeddings.” arXiv preprint arXiv:2402.14776 (2024).https://arxiv.org/pdf/2402.14776v1
- https://sbert.net/examples/training/matryoshka/README.html
- https://velog.io/@hoon_lander/posts
- https://openai.com/index/new-embedding-models-and-api-updates/