STS Project 회고
프로젝트를 마치며
부스트캠프에서 첫 팀 프로젝트로 캐글형식의 대회를 진행했다. 회고를 쓴 시점에서 최종순위가 나온것은아니지만 대략적인 얼개는 나온것같다. 결론부터 말하면 중간정도의 성적이다. 애당초 시작할때 높은 순위가 목표도 아니었고 또 지속적으로 해온 대회라 데이터의 누적으로 순위가 사소한 차이로 갈렸기 때문에 큰 의미는 두지 않아도 될것 같다. 하지만 그렇다고 아쉬움이 없었던것은 아니다. 추석 연휴가 끼어있어서 상당히 길게 프로젝트를 진행했음에도 미숙하게 한점이 많은것같다. 이는 대체로 나의 잘못인데 밑에서 자세히 적도록 하겠다. 대회는 STS(sematical text similarity) 문제로 두 문장의 유사도를 점수로 나타내고 이를 피어슨 상관계수로 평가하는 형식이었다. 기본적으로 base 코드도 주어지기때문에 큰 틀은 여느 팀이나 비슷했다. 그래서 대회중에 색다른 시도를 몇가지 해보고자 했는데 그에대해 먼저 적어볼까 한다.
Loss function의 설계
내가 대학원에 있을때, 리소스도 빈약하고 또 아이디어도 특출난게 없으면 만지는것이 손실함수의 설계였다. 아무래도 가성비가 좋다랄까. 특히 비전쪽은 더욱 그러한면이 있었었다. 당연히 근래의 연구트렌드는 이와 먼것이 사실이다. 특히 자연어 처리는 더욱 그럴것이다. 그 이유는 당연 LLM의 등장으로 모델크기와 데이터의 양이 더 중요해져서 이기도하고 이 때문에 학습시간은 더욱 길어져 새로운 손실함수를 설계하고 검증하는일은 성능향상폭에 비해 가성비가 나쁘기 때문이다. 그래도 이번 task는 학습시간이 길지도 않고 기존에 학습되어있는 모델을 새로운 데이터로 fine-tuning하는것이기 때문에 시도해볼만하다고 생각해서 새로운 손실함수를 설계했다.
설계한 손실함수는 다음과 같다.
$$\mathcal{L}_{cor} = 1 - \rho(y, \hat{y})$$
$$\rho(y, \hat{y}) = \frac{\sum_{i=1}^{n} (y_i - \bar{y})(\hat{y}_i - \bar{\hat{y}})}{\sqrt{\sum_{i=1}^{n} (y_i - \bar{y})^2} \sqrt{\sum_{i=1}^{n} (\hat{y}_i - \bar{\hat{y}})^2}}$$
즉 상관계수 손실함수는 타겟데이터와 예측데이터의 피어슨 상관계수를 구하고 그 값을 1에서 뺀것으로 정의했다. (손실값을 작게 학습해야함으로) 그리고 이것만으로는 선형관계 파악에만 학습이 치중될거같다는 가정을하고 $ L_1 $ 손실함수와 가중합을 더해 최종 손실함수를 정의 했다.
$$ \mathcal{L}_{total} = (1-\alpha)\mathcal{L}_{cor} + \alpha\mathcal{L}_{MAE} $$
이렇게 설계한 이유는 우리가 원하는게 정확한 데이터의 값이 아니라 두 데이터의 상관관계가 선형이 되길 원하기 때문이고 이렇게 설정한 손실함수가 변수들간의 관계를 더 잘 학습할 수 있을거라고 (즉 선형성 파악에 유리) 생각했기 때문이다. 다양한 $\alpha$ 값으로 훈련을 진행해보았는데 결과적으로 $\alpha$ 값이 작을 수록 성능이 좋았고 0.1 정도로 주었을때 사용하지 않을때랑 성능이 비슷했다. 정확히 따지면 학습시에는 모두 성능이 사용하지않는것보다 우수했는데 제출 데이터는 그렇지 않았던 것이다. 이는 과적합이 발생했다고 해석했는데 과적합이 발생한 이유는학습 데이터를 기반으로 선형성을 학습하게 되는데 과연 언어 데이터가 정말 선형적인가 하는 문제이다. 정확히는 언어의 유사도 변수들이 서로 선형적인 관계인가 하는 문제이다. 학습데이터를 공개할 수 없기때문에 적절히 바꾸어서 예를 들어보겠다.
| sentence 1 | sentence 2 | score |
|---|---|---|
| 나는집에 간다 | 나는 집에간다 | 5.0 |
| 너는 사과를 먹는다 | 너는 사과를먹는다 | 4.8 |
| 그는 시계를 샀다 | 그는시계를샀다 | 4.6 |
(📍 저작권상 내가 문장을 적절히 만든것이고 실제 데이터도 비슷한 양상정도라고만 이해해주길 바란다.)
위 데이터에서 첫번째 문장쌍과 두번째문장쌍, 그리고 세번쨰 문장쌍에서 차이점은 띄어쓰기 위치, 그리고 횟수 정도이다. 그런데 이로부터 점수의 선형적인 차가 곧 의미의 차라고 볼 수 있을까? 나는 이런점에 있어서 설계한 손실함수가 적절하지 않았던게 아닌가 싶다.
이 설계의 아쉬웠던점은 논리적이고 수학적인 가설과 검증을 했다기보다는 감각적으로 수행했다는 점이다. 통계적인 background 부족과 경험 부족 때문이 아닐까 싶지만 구현도 실험도 그렇게 많은 노력이 들지 않았기 때문에 크게 아쉬운 부분은 아니다.
Multi-task learning 설계
다음으로 시도했던 색다른 시도는 multi task learning을 시도했다. 학습데이터의 레이블은 두개가 주어졌는데, 비슷한 정도를 나타내는 ’label’ 과 비슷한지 아닌지를 이분법적으로 구분하는 ‘binary-label’이 있었다. base코드에는 후자의 레이블을 전혀 사용하지 않았는데 이를 사용하고자 mult-task learning 을 구현했고 설계는 다음과 같다.
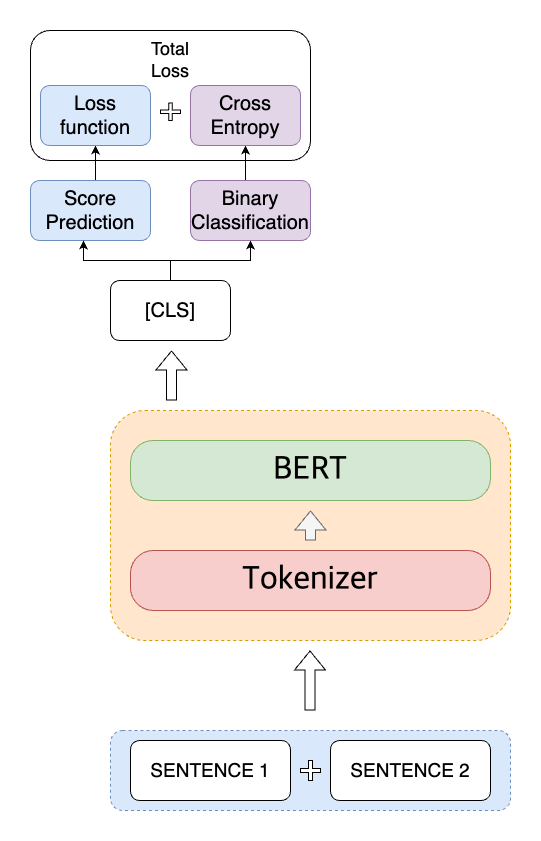
하지만 이 역시 크게 개선된 효과는 보이지 못했다. 장점이 아주 없던것은 아니었는데 학습의 수렴속도는 제법빨라져서 적은 epoch수로도 비슷한 점수를 달성했다.
협업에대해
아번 프로젝트에서 가장 아쉬웠던점은 나의 태도가 아닐까 싶다. 우리팀에서 아무래도 내가 가장 연장자였고 경험도 많았다. 하지만 내가 나서서 업무를 조정하거나 일정 조율을 하지는 않고 특별히 이런걸 정하지 않고 각자해서 합치자 이런식으로 진행하게 되었는데 이게 실수였다. 결과적으로 내코드만으로 결과물을 내고 제출하게 되었다. 팀원들이 경험이 있는 친구도 있었고 없는 친구도 있었는데 없는 친구들에 대한 배려가 부족했던것이다. 이 친구들은 어떤식으로 갈피를 잡아야할지 몰라서 사실상 적극적으로 프로젝트에 참여하기 어려웠는데 이런 팀원들이 참여할수있게끔 역할을 했어야 했다. 대체로 또래집단에서는 나서기보다는 내 할것만 충실히했고 한편으로는 나서서 일을 분배하고 조정하는 일을 주제넘는 일이라고 생각한 부분이 있었던것 같다. 그런데 이번경우 내위치에서는 그렇게 하지않는것이 오히려 책임회피가 아니었나 싶다. 이번 프로젝트는 혼자서 감당할만한 수준이었지만 규모가 더 크고 혼자 개발하기 어려운 과제였다면 분명 파행이 났을거라고 생각한다. 협업할때 있어서 주도적으로 할 수 있는 위치에 있는 사람이 주도적으로 진행해야만 하는게 책임감 있는거라는 생각이 들었고 다음번에는 같은 실수를 하지않도록 다짐하면서 회고를 마친다.