torch.compile 탐구생활
TL;DR
torch.compile()는 데코레이터 한 줄로 PyTorch 코드를 가속해주지만, 그 뒤에는 네 개의 컴포넌트(TorchDynamo, AOTAutograd, PrimTorch, TorchInductor)가 Python 바이트코드부터 Triton 커널까지 다루는 완전한 컴파일러 파이프라인이 돌아가고 있다. 본 글은 내부 구조를 해부하고, MLsys 실무 및 학습 과정에서 마주치는 지점들(재컴파일, 커스텀 op, AOT Inductor, CUDA Graph, 디버깅)까지 한 번에 정리한다.본 글은 torch 2.4.1 기준이다.
0. 왜 torch.compile인가
PyTorch는 오랫동안 “동적(eager)” 실행으로 개발 생산성을 얻고, 성능은 TorchScript/FX로 정적화하여 챙기는 이중 구조였다. 문제는 TorchScript는 쓰기 어려웠고, FX는 데이터 의존적 제어 흐름을 만나면 그대로 깨졌다는 것이다. 결국 대부분의 모델은 eager로 학습하고, 배포 시점에 별도로 TensorRT/ONNX로 변환하는 우회로를 탔다.
PyTorch 2.x의 torch.compile은 이 구조를 근본적으로 다시 짰다:
- 코드 변경 최소화:
model = torch.compile(model)한 줄. - 동적 제어 흐름 지원:
if x.sum() > 0:같은 tensor-dependent 분기도 그래프 break로 해결하되 외곽은 계속 최적화. - 자동 backward 캡처: AOTAutograd가 joint forward/backward 그래프를 만들고 max-flow/min-cut으로 재계산 최적화까지 수행.
- Triton 코드 생성: 대부분의 pointwise/reduction op을 하나의 Triton 커널로 합쳐 메모리 트래픽을 줄임.
ML 시스템 엔지니어 관점에서 중요한 건 결과적으로 Python/프레임워크 오버헤드가 줄고, 메모리 바운드 커널이 퓨전되고, CUDA Graph가 자동으로 붙는다는 점이다. 추론 엔지니어에게는 AOT Inductor로 ahead-of-time 컴파일해서 서빙까지 갈 수 있는 길도 열렸다.
1. 큰 그림: 4개 컴포넌트
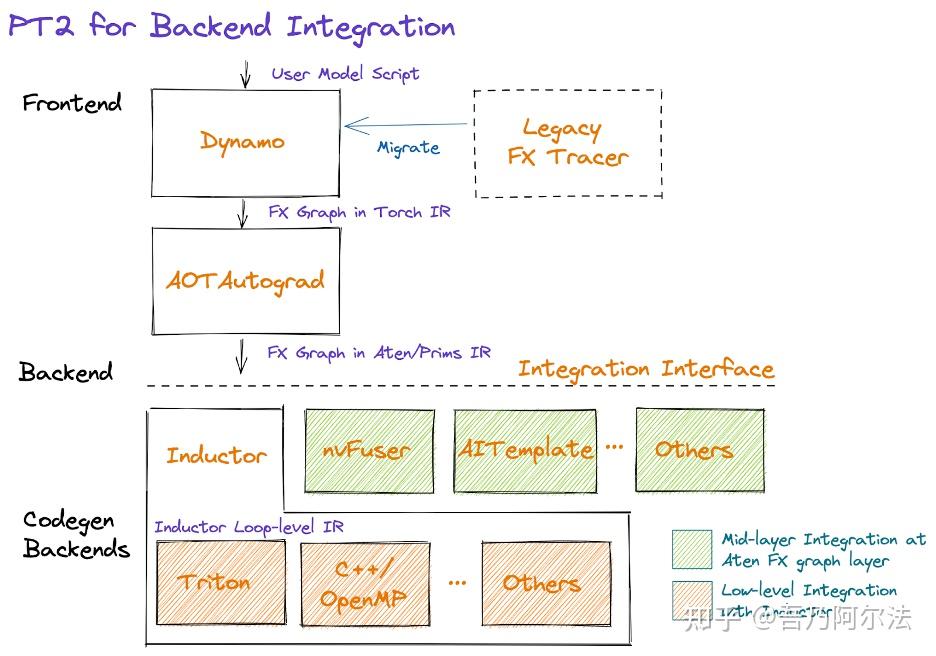
사용자 모델 코드
│
▼
[TorchDynamo] # Python 바이트코드 레벨에서 FX Graph 캡처 (프런트엔드)
│ FX Graph (torch IR)
▼
[AOTAutograd] # 순방향/역방향 joint graph 생성, decompose
│ FX Graph (aten/prims IR)
▼
[PrimTorch] # 2000+ op → ~250 primitives로 정규화
│
▼
[TorchInductor] # Inductor IR로 하강, fusion, codegen
│
▼
Triton(GPU) / C++·OpenMP(CPU) 커널
- TorchDynamo: PEP 523을 사용해 CPython의 프레임 평가 함수를 훅하고, 실행 직전에 바이트코드를 시뮬레이션하면서 FX Graph를 만든다. 지원 못 하는 연산을 만나면 graph break로 그래프를 쪼개고, 해당 지점은 Python 인터프리터가 실행한다.
- AOTAutograd:
__torch_dispatch__메커니즘으로 op dispatch를 가로채서 순/역방향 joint graph를 만들고,partition_fn으로 둘을 분리한다. - PrimTorch: Composite op을 더 낮은 수준의 aten/prims op으로 분해한다. 벤더 입장에서 커널 최적화 대상을 250개 정도로 줄여주는 규약이다.
- TorchInductor: FX Graph를 Inductor IR로 하강시키고, Scheduler가 연산자 융합을 수행한 뒤 Triton 또는 C++ 코드를 생성한다.
이 4개 모두 Python으로 작성되어 있다는 점이 PyTorch 1.x 대비 중요한 변화다. 벤더와 개발자가 직접 손 넣을 수 있게 됐다.
2. 사용법 Basics
2.1 기본 형태
import torch
# 방식 1: 함수 감싸기
def f(x, y):
return torch.sin(x) + torch.cos(y)
opt_f = torch.compile(f)
out = opt_f(torch.randn(10, 10), torch.randn(10, 10))
# 방식 2: 데코레이터
@torch.compile
def g(x, y):
return torch.sin(x) + torch.cos(y)
# 방식 3: nn.Module
model = torch.compile(MyModel().cuda())
torch.compile은 실제로는 torch._dynamo.optimize의 얇은 래퍼다:
def compile(model=None, *, fullgraph=False, dynamic=None,
backend="inductor", mode=None, options=None, disable=False):
# ...
return torch._dynamo.optimize(backend=backend, nopython=fullgraph,
dynamic=dynamic, disable=disable)(model)
즉, torch.compile을 호출한다고 실제 컴파일이 일어나는 게 아니다. 함수가 처음 호출되는 시점에야 비로소 Dynamo가 바이트코드를 훅하고 컴파일이 시작된다. 이 “처음 한 번의 지연"은 모든 JIT 컴파일러의 공통 특성이자, 프로덕션에서 워밍업을 반드시 해야 하는 이유다.
2.2 백엔드와 모드
import torch._dynamo as dynamo
dynamo.list_backends()
# ['cudagraphs', 'inductor', 'onnxrt', 'openxla', 'tvm']

| backend | forward | backward | 그래프 최적화 |
|---|---|---|---|
eager |
Dynamo | N/A | 없음 |
aot_eager |
Dynamo | AOTAutograd | 없음 |
inductor (기본) |
Dynamo | AOTAutograd | Inductor |
cudagraphs |
Dynamo | AOTAutograd | CUDA Graph |
| 커스텀 | Dynamo | AOTAutograd | 직접 구현 |
디버깅 순서는 eager → aot_eager → inductor가 정석이다. 먼저 Dynamo가 그래프를 제대로 캡처하는지, 다음으로 backward가 정상인지, 마지막으로 Inductor의 최적화가 문제를 일으키지 않는지를 차례로 확인한다.
모드는 4가지:
default: 컴파일 시간/메모리 오버헤드 없이 합리적 속도. 대부분의 훈련 시나리오.reduce-overhead: CUDA Graph로 Python/런치 오버헤드 제거. 추론에 적합하지만 GPU 메모리는 더 씀.max-autotune: Triton 템플릿 기반 matmul과 autotuning. 컴파일 오래 걸리는 대신 피크 성능.max-autotune-no-cudagraphs: 위와 같지만 CUDA Graph 미사용.
3. TorchDynamo — 프런트엔드 그래프 캡처
3.1 JIT 컴파일러의 기본 구조
PyTorch 컴파일러는 Just-In-Time 컴파일러다. JIT의 핵심은 두 가지: 가드(guard) 와 변환된 코드(transformed code).
def f(x, mod):
for guard, transformed_code in f.compiled_entries:
if guard(x, mod):
return transformed_code(x, mod)
try:
guard, transformed_code = compile_and_optimize(x, mod)
f.compiled_entries.append([guard, transformed_code])
return transformed_code(x, mod)
except FailToCompileError:
return original_code(x, mod) # fallback
Dynamo는 입력이 들어올 때마다 등록된 가드들을 하나씩 확인한다. 맞는 게 있으면 그 변환 코드를 실행하고, 없으면 새로 컴파일해서 엔트리를 추가한다. 하나의 Python code object에 대해 기본 캐시 크기는 64이고, 이를 넘으면 해당 함수는 더 이상 컴파일하지 않고 eager로 돌린다.
3.2 PEP 523과 CPython 훅
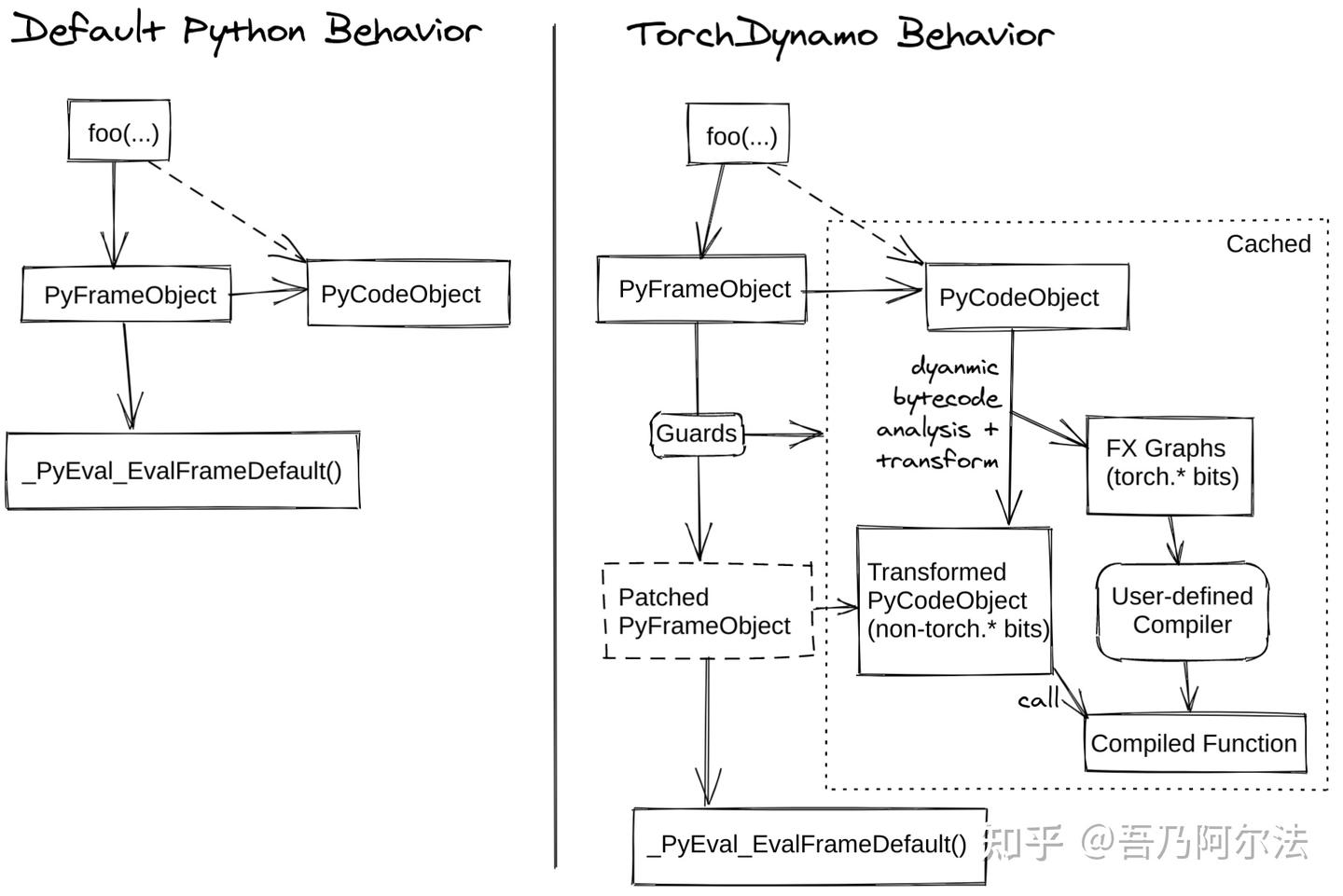
좌측이 기본 CPython의 함수 실행 흐름이다. foo() 호출 시 CPython은 PyCodeObject(바이트코드/상수/변수 테이블)를 기반으로 PyFrameObject(실행 환경)를 만들고, 이를 _PyEval_EvalFrameDefault()에 넘겨 한 바이트코드씩 실행한다.
PEP 523은 이 _PyEval_EvalFrameDefault를 사용자 정의 함수로 교체할 수 있는 C API를 제공한다. Dynamo는 이 API로 custom_eval_frame_shim()을 끼워 넣어서, 바이트코드 실행 직전에 가로채고 분석한다. 우측 그림처럼:
PyFrameObject를 받는다.- 이 프레임의
PyCodeObject에 이미 캐시된 변환 결과가 있는지 확인한다. - 있고 guard가 통과하면 변환된 코드를 실행한다.
- 없으면 dynamic bytecode analysis + transform을 수행해서 FX Graph와 patched PyFrameObject를 만들고 캐시한다.
3.3 바이트코드 시뮬레이션 → FX Graph
Python의 가상 머신은 스택 머신이다. 이해를 위한 예:
import dis
def hello():
print("Hello, world!")
dis.dis(hello)
출력:
0 LOAD_GLOBAL 0 (print)
2 LOAD_CONST 1 ('Hello, world!')
4 CALL_FUNCTION 1
6 POP_TOP
8 LOAD_CONST 0 (None)
10 RETURN_VALUE
Dynamo는 이 바이트코드를 실제로 실행하지 않고 시뮬레이션한다. 그 과정에서 PyTorch 연산을 만나면 FX Graph에 노드를 추가한다. 예를 들어:
@torch.compile(backend=my_compiler)
def foo(x, y):
return (x + y) * x
이 함수는 다음 바이트코드로 컴파일된다:
0 LOAD_FAST 0 (x)
2 LOAD_FAST 1 (y)
4 BINARY_ADD ← FX node: operator.add
6 LOAD_FAST 0 (x)
8 BINARY_MULTIPLY ← FX node: operator.mul
10 RETURN_VALUE
Dynamo는 BINARY_ADD, BINARY_MULTIPLY를 만날 때 각각 FX Node를 생성해서 최종 FX Graph를 만든다:
opcode name target args kwargs
------------- ------ ----------------------- --------- --------
placeholder x x () {}
placeholder y y () {}
call_function add <built-in function add> (x, y) {}
call_function mul <built-in function mul> (add, x) {}
output output output ((mul,),) {}
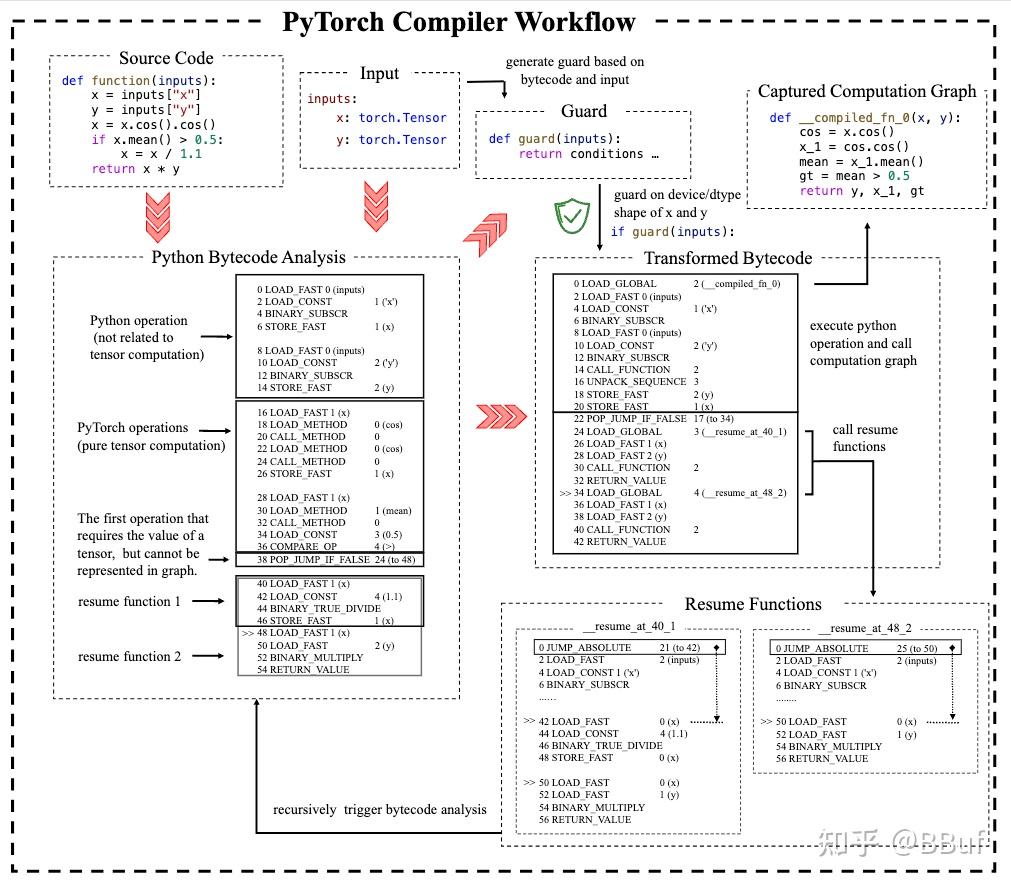
이 그림은 더 복잡한 함수에서의 전체 흐름을 보여준다. Source Code → Input → Guard 생성 → 바이트코드 분석 → Python 연산(텐서 계산 무관) 과 PyTorch 연산(순수 계산 그래프) 을 분리 → Transformed Bytecode → Guard 실패 시 Resume Function을 호출하고 재귀적으로 다시 분석.
3.4 Guard 시스템
Dynamo가 만드는 guard의 예:
GUARDS ___guarded_code.valid and ___check_tensors(x, y)
런타임에 x, y의 device/dtype/shape/stride가 변했는지 C++ 함수로 빠르게 체크한다. 변하지 않았으면 컴파일된 코드 재사용, 변했으면 재컴파일.
기본 guard 대상:
- 텐서: device, dtype, shape, stride, requires_grad, layout
- 스칼라: 값 자체 (예:
n=4이면n=4만 특화) - 컨테이너: len, 각 원소 타입
- nn.Module:
__dict__의 특정 속성
이 때문에 Python 리스트의 원소를 매번 바꿔서 넘기거나 스칼라 인자가 매번 달라지면 재컴파일이 유발된다. 프로덕션에서는 TORCH_LOGS="recompiles"로 원인을 추적할 수 있다.
3.5 Graph Break
Dynamo가 처리 못 하는 걸 만나면 그 지점에서 그래프를 자른다:
def toy_example(a, b):
x = a / (torch.abs(a) + 1)
if b.sum() < 0: # ← 여기서 graph break
b = b * -1
return x * b
결과적으로 다음과 같이 3개의 그래프로 나뉜다:
def compiled_toy_example(a, b):
x, lt = __compiled_fn_0(a, b) # if 이전
if lt:
return __resume_at_30_1(b, x) # if 분기
else:
return __resume_at_38_2(b, x) # else 분기
__resume_at_*는 Dynamo가 바이트코드에 직접 생성한 이어가기 함수로, 해당 함수가 처음 실행될 때 다시 Dynamo에 의해 캡처/컴파일된다.
Graph break는 조용한 성능 킬러다. 너무 많이 발생하면 각 서브그래프가 너무 작아서 컴파일 이득이 사라지거나, CUDA Graph가 아예 붙지 못한다. fullgraph=True로 첫 break 시 에러를 내게 해서 점검하는 습관을 들이자:
model = torch.compile(model, fullgraph=True) # break 시 예외
혹은:
torch._dynamo.explain(f, *args) # 어디서 break가 났는지 보고서 출력
3.6 루프 언롤링과 함수 인라이닝
- 루프: Dynamo는 Python for/while을 언롤링한다.
for i in range(1, 5):는 곱셈 4번을 그대로 펼친 그래프가 된다. 런타임 변수n이 guard로 특화되므로,n이 바뀌면 재컴파일된다. - 함수 호출: 기본적으로 인라이닝한다. 호출된 함수가 다시 break를 일으키지 않는 한 한 그래프로 합친다. 재귀 함수도 인라이닝 대상이다.
- 데이터 의존 조건문: 인라이닝 실패 → 호출자에게까지 break가 전파된다.
3.7 DDP와 DistributedDataParallel
DDP는 bucket 경계에서 allreduce를 호출해 통신과 backward를 오버랩한다. Dynamo가 모델 전체를 하나의 그래프로 캡처해버리면 모든 allreduce가 backward 끝까지 기다려야 해서 오버랩이 깨진다. 그래서 Dynamo는 DDP bucket 경계에 의도적으로 graph break를 삽입한다. EfficientNet-B0를 bucket 4MB로 쓸 때 5개 서브그래프로 쪼개지는 이유가 이것이다.
4. AOTAutograd — 순/역방향 joint 그래프
4.1 왜 필요한가
Dynamo가 캡처한 FX Graph는 순방향만 담고 있다. PyTorch의 역방향은 순방향을 실행하면서 autograd tape에 동적으로 기록되는 구조라, 순방향을 컴파일해도 역방향은 여전히 동적이다. 훈련 시나리오를 최적화하려면 backward도 미리 뽑아내야 한다.
4.2 __torch_dispatch__ 메커니즘
PyTorch의 핵심은 dispatcher다. 한 연산자는 입력 텐서의 속성에 따라 여러 번 dispatch를 거친다(autograd → autocast → CPU/CUDA kernel). __torch_dispatch__는 이 dispatch 과정에 Python 레벨에서 끼어들 수 있는 훅이다.
AOTAutograd는 ProxyTorchDispatchMode로 이 훅을 설정한다. op dispatch가 일어날 때마다 dispatch 이전에:
- Proxy 생성: 해당 op을 FX Graph에
call_function타입 노드로 추가하고, 결과에 Proxy를 바인딩 - decompose: high-level op을 더 낮은 primitive로 분해
이를 실제 함수 실행과 병행하면서 FX Graph가 점진적으로 만들어진다.
4.3 joint graph 구축
call_user_compiler()
└── compile_fx(): inductor 구현
└── aot_dispatch_autograd(): joint graph 캡처 및 분할
├── aot_dispatch_autograd_graph(): fw-bw joint graph 캡처
│ ├── create_joint(): 순/역방향 계산을 joint_fn_to_trace로 캡슐화
│ └── _create_graph() → make_fx() → _MakefxTracer.trace()
│ ├── dispatch_trace(): 입력에 placeholder Proxy 생성
│ └── decompose() 컨텍스트: ProxyTorchDispatchMode
│ └── __torch_dispatch__(): op별 call_function Proxy 생성 + decompose
└── partition_fn(): joint graph를 fw/bw로 분할
├── default_partition: 중간 결과 전부 backward에 전달
└── min_cut_rematerialization_partition: 일부 재계산으로 메모리 절약
예시로 my_func(x) = cos(cos(x)):
# joint graph
placeholder primals_1
placeholder tangents_1
call_function cos aten.cos.default (primals_1,)
call_function cos_1 aten.cos.default (cos,)
call_function sin aten.sin.default (cos,)
call_function neg aten.neg.default (sin,)
call_function mul aten.mul.Tensor (tangents_1, neg)
call_function sin_1 aten.sin.default (primals_1,)
call_function neg_1 aten.neg.default (sin_1,)
call_function mul_1 aten.mul.Tensor (mul, neg_1)
output ([cos_1, mul_1],)
순방향은 cos_1을 반환하고, 역방향은 mul_1 (= dL/dx)을 반환한다.
4.4 partition — forward/backward 분할
두 가지 전략:
default_partition: forward의 모든 중간 결과를 backward를 위해 보존. PyTorch 기본 동작과 동일.min_cut_rematerialization_partition(Inductor 기본): activation checkpointing의 자동판. forward의 어떤 tensor를 backward에 넘길지, 어떤 걸 재계산할지를 최대유량-최소컷 그래프 문제로 풀어 메모리와 계산 간 tradeoff를 최적화한다.
위 my_func 예시에서 min-cut 분할 결과:
forward graph:
placeholder primals_1
call cos (primals_1,)
call cos_1 (cos,)
output ([cos_1, primals_1],) # cos는 저장하지 않음!
backward graph:
placeholder primals_1, tangents_1
call cos (primals_1,) # 재계산
call sin (cos,)
call neg (sin,)
...
순방향에서 중간값 cos를 메모리에 저장하지 않고, 역방향에서 cos(primals_1)을 재계산한다. 현대 GPU는 메모리 바운드라 약간의 재계산이 큰 메모리 절감보다 싸다.
5. PrimTorch — op 세계의 단순화
PyTorch에는 2,198개의 op이 있다. 이걸 벤더가 하드웨어별로 다 커널을 짜는 건 불가능하다.
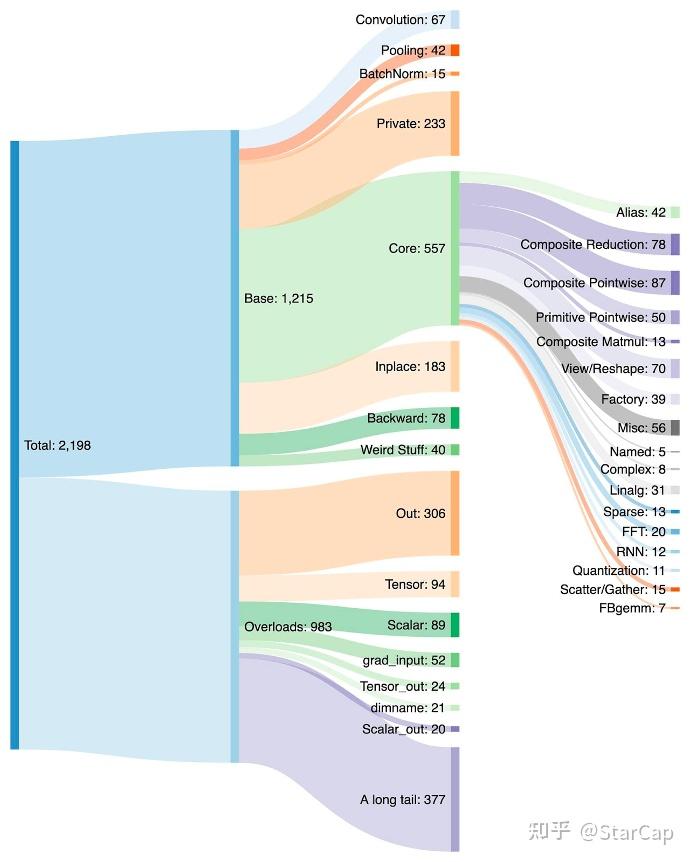
PrimTorch는 Composite Implicit Autograd dispatch key를 활용해서 high-level op을 더 낮은 수준의 aten/prims primitive로 자동 분해한다. 최종적으로 벤더가 다뤄야 할 op은 ~250개 수준의 폐쇄 집합으로 줄어든다. CURRENT_DECOMPOSITION_TABLE에서 decomposition 함수를 찾고, 없으면 decompose()로 계속 내려간다:
def decompose(self, *args, **kwargs):
dk = torch._C.DispatchKey.CompositeImplicitAutograd
if dk in self.py_kernels:
return self.py_kernels[dk](*args, **kwargs)
elif torch._C._dispatch_has_kernel_for_dispatch_key(self.name(), dk):
return self._op_dk(dk, *args, **kwargs)
return NotImplemented
커스텀 op은 기본적으로 decompose되지 않는다. Inductor는 이걸 ExternKernel(= fallback)로 취급한다.
6. TorchInductor — 백엔드 컴파일
6.1 compile_fx의 전체 흐름
compile_fx_inner()
├── fx_codegen_and_compile()
│ ├── _recursive_post_grad_passes(): 그래프 최적화
│ │ ├── group_batch_fusion_passes: batch_linear/batch_relu 융합
│ │ ├── remove_noop_ops: aten.clone / aten.alias 제거
│ │ ├── fuse_ddp_communication: DDP 통신 융합
│ │ └── decompose_auto_functionalized: high-level op 추가 분해
│ ├── GraphLowering: FX Graph → Inductor IR
│ └── GraphLowering.compile_to_fn(): 하드웨어용 커널 코드 생성
│ ├── Scheduler.__init__(): 연산자 융합
│ │ ├── compute_dependencies
│ │ └── fuse_nodes
│ │ ├── get_possible_fusions
│ │ ├── score_fusion
│ │ └── can_fuse
│ └── Scheduler.codegen(): Triton/C++/OpenMP 코드 생성
└── cudagraph: reduce-overhead 모드일 때 추가
├── has_incompatible_cudagraph_ops
└── cudagraphify
6.2 GraphLowering — FX → Inductor IR
FX Graph의 각 node를 Inductor IR로 바꾼다. Inductor IR의 세 가지 주요 유형:
- PointWise: 원소별 계산. 메모리에 저장하지 않음. 계산 로직은
inner_fn(index)함수로 기술됨. - InputBuffer: 입력 텐서. 실제 메모리 할당.
- ComputedBuffer: 중간 결과 또는 출력. 실제 메모리 할당.
aten.sum같은 reduction이나 output으로 쓰이는 노드가 여기 해당.
예를 들어 torch.floor(x) + torch.ceil(x)에서 aten.add의 inner_fn은 aten.floor와 aten.ceil의 inner_fn을 그대로 인라인해서 재사용한다:
def inner_fn(index):
i0, i1, i2 = index
tmp0 = ops.load(arg0_1, i2 + 1024 * i1 + 524288 * i0)
tmp1 = ops.floor(tmp0)
tmp2 = ops.load(arg0_1, i2 + 1024 * i1 + 524288 * i0)
tmp3 = ops.ceil(tmp2)
return tmp1 + tmp3
이 시점에 이미 pointwise fusion이 일어난다. GraphLowering이 끝나면 실제 메모리 저장이 있는 Buffer만 남는다.
6.3 Scheduler — op 융합의 본체
Inductor IR에서 각 Buffer가 하나의 메모리 공간에 대응한다. Scheduler는 두 노드가 공유 메모리 접근을 가지면 융합하여 Triton 커널 하나로 합친다.
fuse_node(): fuse_nodes_once()를 10회 루프
└── fuse_nodes_once(): 1회 분의 연산자 융합
├── get_possible_fusions(): 융합 가능한 후보 노드 쌍
│ ├── check_all_pairs: 동일 입력 파라미터 노드끼리 can_fuse 체크
│ └── score_fusion_key: 점수를 매기고 내림차순 정렬
├── 후보 노드 쌍 효과 판단
│ ├── can_fuse(): 규칙 충족 여부
│ ├── will_fusion_create_cycle(): 순환 형성 여부
│ └── speedup_by_fusion(): 환경 변수 시 실측
└── 정식 연산자 융합
can_fuse() 판단 규칙:
can_fuse() 판단 규칙
├── 기초 판단
│ ├── node1과 node2는 동일 Node일 수 없음
│ ├── ExternKernelSchedulerNode / NopKernelSchedulerNode은 융합 제외 (Template 제외)
│ ├── device가 달라서는 안 됨
│ ├── 공통 데이터 접근이 있어야 함
│ └── 융합 후 노드 수 ≤ config.max_fusion_size (기본 64)
└── 핵심 판단 함수
├── 수직 융합 (node2가 node1의 출력에 의존)
│ ├── Scheduler.can_fuse_vertical: node2 읽기 ⊇ node1 쓰기
│ └── backend.can_fuse_vertical
└── 수평 융합 (상호 독립, 동일 입력)
├── Scheduler.can_fusion_increase_peak_memory
└── backend.can_fuse_horizontal
score_fusion 점수:
memory_score: 두 노드가 공유하는 메모리 접근의 크기(읽기/쓰기 인덱스가 완전히 일치해야 카운트)proximity_score: 그래프 상 토폴로지 거리. 멀리 있는 노드를 융합하면 tensor lifetime이 길어져서 peak memory가 증가하므로 가까운 쌍을 우선
백엔드(SIMDScheduling.can_fuse())는 궁극적으로 “이 두 노드를 합친 Triton 커널을 합리적으로 codegen할 수 있느냐” 만 본다. 주로 두 노드의 size가 완전 일치하고 융합 전후 tiling이 동일한지를 체크한다.
6.4 세 층위의 연산자 융합
정리하면 Inductor는 세 층위에서 fusion을 한다:
- FX Graph level: target이 torch.ops 수준일 때. 조대한 입도의 융합(예: 추론 시 Conv+BN → 새 Conv). 훈련에서는 역전파 함수가 제공되어야 해서 제한적.
- GraphLowering inline: Pointwise/Reduction의
inner_fn인라인. 순수 계산의 중간 결과는 저장하지 않고 바로 재사용. - Inductor IR level (Scheduler): 실제 Buffer 간 공유 메모리 기반 융합. 핵심 메모리 절감 포인트.
7. ML 시스템 엔지니어를 위한 실전 가이드
여기부터는 공식 튜토리얼이 잘 다루지 않는, 프로덕션에서 밟게 되는 지뢰들이다.
7.1 어떤 mode를 언제 쓸 것인가
| 상황 | 권장 mode | 이유 |
|---|---|---|
| 일반 훈련 | default |
컴파일 비용/메모리 균형 |
| 추론 (지연 민감) | reduce-overhead |
CUDA Graph로 런치 오버헤드 제거 |
| 추론 (처리량 극한) | max-autotune |
Triton matmul template autotuning |
| 다양한 shape 섞임 | default + dynamic=True |
재컴파일 방지 |
reduce-overhead는 CUDA Graph를 자동으로 붙여준다. 단, CUDA Graph는 입력 포인터가 매 호출마다 동일해야 하므로, Inductor가 입력을 정적 버퍼로 복사한다. 결과적으로 메모리 사용량이 증가하고, batch size가 바뀌면 재캡처 비용이 든다.
7.2 첫 컴파일 지연과 캐시
# 추론 서버 기동 시 반드시 워밍업
for _ in range(3):
_ = compiled_model(sample_input)
torch.cuda.synchronize()
Inductor는 컴파일 결과를 디스크에 캐시한다:
export TORCHINDUCTOR_CACHE_DIR=/var/cache/torch_compile
기본은 /tmp/torchinductor_<user>. 컨테이너 배포 시 볼륨 마운트로 영속화하면 restart마다 재컴파일이 사라진다. 캐시 키에는 모델 구조, dtype, shape(dynamic 아니면), CUDA/Triton 버전이 들어간다.
PyTorch 2.3+부터는 FxGraphCache가 더 aggressive하게 재사용되고, 2.4+는 torch._inductor.config.fx_graph_remote_cache = True로 Redis 등 원격 캐시도 가능해졌다.
7.3 동적 shape 전략
기본 동작: 첫 호출에서 shape 특화 → 다른 shape 들어오면 자동으로 dynamic 시도 → 실패 시 재컴파일.
실무에서는 이 자동 판단이 의도를 못 맞출 때가 있다. 추론 서버처럼 batch size가 들쭉날쭉하면 명시적으로:
model = torch.compile(model, dynamic=True)
주의: shape 0과 1은 자동으로 specialize된다(broadcasting 의미 때문). batch=1이 섞이면 별도 컴파일 엔트리가 생긴다.
# mark_dynamic으로 특정 차원만 동적화
torch._dynamo.mark_dynamic(tensor, 0) # 0번째 dim만 dynamic
7.4 Recompilation 관리
export TORCH_LOGS="recompiles"
# 또는 더 상세히
export TORCH_LOGS="recompiles_verbose"
이러면 stderr에 어떤 guard가 실패했는지 나온다. 흔한 원인:
- Python int/float 상수가 매번 달라짐 → 해당 인자를 tensor로 바꾸거나 lambda closure로 가둠
- 리스트의 len이 매번 달라짐
- nn.Module의 속성이 forward 안에서 수정됨
isinstance검사 대상이 바뀜
캐시 한도가 꽉 차면(기본 64) Dynamo가 “recompile limit reached"를 찍고 더 이상 컴파일하지 않는다. 크게 잡는 것보다 원인을 없애는 게 정석이지만, 정당한 경우라면:
torch._dynamo.config.cache_size_limit = 128
7.5 커스텀 op 등록
PyTorch 2.4+부터 torch.library.custom_op으로 깔끔하게 등록할 수 있다:
import torch
from torch import Tensor
@torch.library.custom_op("mylib::fused_mul_add", mutates_args={})
def fused_mul_add(x: Tensor, y: Tensor, z: float) -> Tensor:
return x * y + z
@fused_mul_add.register_fake
def _(x, y, z):
torch._check(x.device == y.device)
torch._check(x.shape == y.shape)
return torch.empty_like(x)
def _backward(ctx, grad):
x, y = ctx.saved_tensors
return grad * y, grad * x, None
def _setup_context(ctx, inputs, output):
x, y, z = inputs
ctx.save_for_backward(x, y)
torch.library.register_autograd(
"mylib::fused_mul_add", _backward, setup_context=_setup_context)
register_fake은 FakeTensor propagation용 — shape/device 메타데이터를 계산해서 컴파일러가 실제 텐서 없이 그래프 추론을 할 수 있게 해준다. register_autograd가 없으면 역전파 지원이 빠진 채 등록된다.
주의: 커스텀 op은 Inductor가 decompose하지 않고 ExternKernel로 fallback 처리한다. Scheduler 융합에도 참여하지 않는다. 즉 커스텀 op 자체가 충분히 크고 최적화되어 있어야 한다.
7.6 커스텀 fusion pass
Inductor의 post_grad pass 훅에 pattern matcher를 등록해서 자동 치환도 가능하다:
from torch._inductor.pattern_matcher import PatternMatcherPass, register_replacement
my_pass = PatternMatcherPass()
def mul_add_pattern(x, y, z):
return x * y + z
def fused_replacement(x, y, z):
return torch.ops.mylib.fused_mul_add(x, y, z)
register_replacement(mul_add_pattern, fused_replacement,
[torch.randn(2, 3), torch.randn(2, 3), 0.5], ...,
pass_dict=my_pass.patterns)
# Inductor에 pass 등록
from torch._inductor import config as inductor_config
inductor_config.post_grad_custom_post_pass = my_pass
사용자가 모델 코드를 고치지 않아도 a*b+c 패턴이 자동으로 custom op으로 바뀐다.
7.7 AOT Inductor — 추론 서빙용 AOT 컴파일
JIT의 한계: 서버 기동 시 워밍업 필요, Python 런타임 의존. 추론 배포에서는 AOT Inductor로 미리 .so까지 빌드할 수 있다:
import torch
with torch.no_grad():
model.eval()
ep = torch.export.export(model, example_args)
path = torch._inductor.aot_compile(
ep.module(), example_args,
options={"aot_inductor.output_path": "model.so"}
)
런타임:
model = torch._export.aot_load("model.so", "cuda")
out = model(input_tensor)
- C++ 런타임이라 Python GIL 없음
- 의존성 최소화 (libtorch + model.so)
- TorchServe, vLLM 등에서 이 경로를 점점 표준 경로로 채택 중
7.8 분산 훈련과의 상호작용
- DDP: 앞에서 본 대로 Dynamo가 bucket 경계에서 자동 break.
model = DDP(torch.compile(module))순서 권장. - FSDP (FSDP1):
use_orig_params=True가 필수. Dynamo가 파라미터 access 패턴을 안정적으로 tracing 하려면 필요. - FSDP2: PyTorch 2.4+의 새 구현은 compile과의 통합이 더 깔끔하다.
torch.distributed._composable.fsdp.fully_shard.
7.9 inference_mode vs no_grad
torch.inference_mode()는 no_grad보다 더 aggressive하지만 Dynamo와 미묘한 상호작용이 있었다(버전마다 다름). 서빙 루프에서는:
with torch.inference_mode():
out = compiled_model(x)
가 일반적으로 권장되지만, 특정 커스텀 op이 inference_mode에서 이상 동작한다면 no_grad로 바꿔보자.
8. 디버깅 & 프로파일링
8.1 환경 변수 치트시트
# 기본 디버그 출력
export TORCH_LOGS="+dynamo,+inductor,graph_breaks,recompiles"
# 생성된 Triton 코드 보기
export TORCH_LOGS="output_code"
# 풀 덤프 (성능 나쁨, 디버그 전용)
export TORCH_COMPILE_DEBUG=1
# → torch_compile_debug/ 에 FX graph, Inductor IR, Triton 코드가 전부 쌓임
# Dynamo 상세 로그
export TORCHDYNAMO_VERBOSE=1
TORCH_LOGS는 ?로 사용 가능한 아티팩트를 나열할 수 있다:
TORCH_LOGS="?" python -c "import torch"
8.2 torch._dynamo.explain
import torch._dynamo as dynamo
explanation = dynamo.explain(my_func, *sample_inputs)
print(explanation)
# graph break count, 각 서브그래프의 op 리스트, break 원인 등을 보고
8.3 depyf
생성된 바이트코드를 사람이 읽을 수 있는 Python으로 역컴파일해 주는 도구. Dynamo가 실제로 뭘 만들었는지 보고 싶을 때 최고:
pip install depyf
import depyf
with depyf.prepare_debug("./depyf_dump"):
compiled_model(x)
# ./depyf_dump/에 변환된 Python 코드가 쌓인다
8.4 성능 측정 올바른 방법
# CUDA 동기 + 반복 평균. 첫 N회는 워밍업으로 버린다.
def bench(fn, iters=50, warmup=10):
for _ in range(warmup):
fn()
torch.cuda.synchronize()
start = torch.cuda.Event(enable_timing=True)
end = torch.cuda.Event(enable_timing=True)
start.record()
for _ in range(iters):
fn()
end.record()
torch.cuda.synchronize()
return start.elapsed_time(end) / iters
time.perf_counter()만 쓰면 CUDA 비동기 때문에 말이 안 되는 숫자가 나온다.
9. 흔한 함정들
print(tensor)는 graph break. 디버깅용 print는 반드시 제거하고 배포..item(),.tolist()등 host 전송도 break. loss logging 같은 건 학습 루프의loss.item()위치를 벗어나지 않게.- Python 딕셔너리 키 순회가 forward에 있으면 key 순서 변경 시 recompile.
- Global 변수 참조는 가능하면 모듈 속성으로 옮겨라. Global mutation은 특히 위험.
torch.cond(2.3+)가 있다. 데이터 의존 분기를 graph break 없이 캡처하고 싶으면 이걸 써라. 단 두 분기 모두 동일한 output structure여야 함.- numpy 호출:
torch.compile이 numpy 인터롭을 제한적으로 지원하지만, 의존하면 debug 지옥. 가능하면 torch로 바꾸자. - nn.Module 속성 추가를 forward에서 금지.
self.cache = ...같은 건__init__에서만. - 첫 호출 지연을 측정값에 포함하지 말 것. 이게 의외로 벤치마크 글들이 자주 틀리는 부분이다.
10. 언제 쓰지 말아야 하는가
- 호출이 드문 함수 (워밍업 비용 회수 불가)
- shape이 매번 크게 다른 함수 (dynamic도 버거운 수준)
- 이미 100% GPU bound에 fusion 여지 없는 단일 거대 matmul
- cuBLAS/cuDNN만으로 충분한 단순 모델 (ResNet-18 정도의 소형 모델은 이득 미미)
- 지원이 불안정한 라이브러리와 깊게 얽힌 코드 (scipy의 특정 호출은 여전히 불안정)
결국 torch.compile이 가장 유용한 곳은:
- 메모리 바운드 pointwise/reduction 체인이 많은 모델 (transformer의 attention 주변, LayerNorm/RMSNorm, activation들)
- Python 오버헤드가 큰 자잘한 op 체인 (많은 작은 텐서 조작)
- 반복 호출이 많은 추론 서버 (워밍업 비용 분산 가능)
11. 생태계와 앞으로의 방향
torch.export: 2.2+부터 stable. Dynamo로 그래프를 캡처해서 직렬화 가능한ExportedProgram으로 빼는 경로. ONNX/TensorRT 경로 대비 장점은 “PyTorch 코드 그대로 export 되고, fallback 없음"이 기본 보장 가능.- AOT Inductor: export한 그래프를 Inductor로 C++/CUDA 코드 생성 후
.so로 빌드. 서빙 경로가 상당히 정리되었다. - vLLM / SGLang: 내부적으로
torch.compile을 적극 활용. LLM 서빙에서 attention kernel, sampling, projection을 어떻게 compile/CUDA Graph로 묶느냐가 처리량의 핵심. - compile-aware 모델 디자인: graph break를 적극적으로 없애는 스타일의 모델 작성 가이드가 퍼지고 있다. (예: attention mask를 매번 새로 만들지 말고 재사용 가능한 형태로 설계)
12. 정리
torch.compile의 핵심은 네 단계의 변환이다:
- Dynamo가 Python 바이트코드에서 FX Graph를 뽑고,
- AOTAutograd가 joint forward/backward 그래프로 확장하며,
- PrimTorch가 수천 개 op을 수백 개 primitive로 분해하고,
- Inductor가 Scheduler로 op을 묶어 Triton/C++ 커널을 생성한다.
ML 시스템 엔지니어의 일은 이 파이프라인의 각 경계에서 정보를 뽑고, 재컴파일을 막고, fallback을 줄이고, 캐시를 관리하는 것이다. 추론 엔지니어라면 추가로 AOT Inductor와 CUDA Graph 경로를 서빙에 맞게 세팅해야 한다.
공식 문서만 보고는 잡히지 않는 감각들 — “이 코드는 왜 매번 recompile되지?”, “이 graph break는 왜 생겼지?”, “왜 내 모델은 fusion이 안 되지?” — 은 결국 위 네 단계 중 어디에서 무슨 일이 일어나는지를 알아야만 답이 나온다. 가장 빠른 습득 방법은 작은 모델로 TORCH_COMPILE_DEBUG=1을 켜고 한 번 끝까지 읽어보는 것이다.
참고자료
- torch.compile 공식 튜토리얼
- PyTorch 2.0: Get Started
- depyf — Dynamo를 읽을 수 있게 해주는 도구
- PEP 523 — Frame evaluation API
- TorchInductor 아키텍처 RFC
- AOT Inductor
- torch.export 튜토리얼
- 본 시리즈 원문(중국어, zhihu.com): 1, 2, 3, 4, 5, 6, 7, 8, 9